
-
史宾格安全及隐私合规平台3分钟完成一周工作量 更快实现隐私合规
-
IP信誉查询多因子计算,多维度画像
-
智能数据安全网关为企业数据安全治理提供一体化数据安全解决方案
-
4网址安全检测
-
5SMS短信内容安全
-
6百度漏洞扫描
-
7爬虫流量识别
-
8百度AI多人体温检测
-
9工业大脑解决方案
-
10APP安全解决方案
-
11企业人员安全意识解决方案
-
12安全OTA
-
13大模型安全解决方案
-
14安全知识图谱
-
15智能安全运营中心AISOC
热门主题




一个有关 V8 漏洞的细节分析 (一)
2021-03-08 11:44:0220248人阅读
当开发人员决定使用新的Torque语言重新实现两个CodeStubAssembler(CSA)函数时,V8中就会出现漏洞。这两个函数用于在JavaScript中创建新的FixedArray和FixedDoubleArray对象,尽管新的实现乍看之下是有效的,但它们缺少一个关键组成部分:最大长度检查,以确保新创建的数组的长度不会超过预定义的上限。
在一般人看来,这个缺失的长度检查看起来很正常,但对于攻击者来说,就可以利用了TurboFan的typer来获取访问权限中的一个非常强大的利用原语:数组,其长度字段远大于其容量。该原语为攻击者提供了V8堆上的越界访问原语,这很容易导致代码执行。
漏洞实现过程
如果要继续,则需要构建V8版本8.5.51(提交64cadfcf4a56c0b3b9d3b5cc00905483850d6559),建议使用完整符号进行构建(修改args.gn并添加symbol_level = 2行)。
在x64.release目录中,你可以使用以下命令以零编译器优化来编译发行版本:
find . -type f -exec grep '\-O3' -l {} ";" -exec sed -i 's/\-O3/\-O0/' {} ";" -ls如果你想继续阅读本博文中的一些代码示例,我仍然建议你构建普通发行版(启用编译器优化)。如果不进行优化,某些示例将花费非常长的时间才能运行。
从上面链接的bugtracker中获取概念证明。
2017年之前的V8
在2017年之前,许多JavaScript内置函数(Array.prototype.concat,Array.prototype.map等)都是用JavaScript本身编写的,尽管这些函数使用了TurboFan(V8的推测性优化编译器,稍后将进行详细说明)。为了最大限度地发挥性能,它们的运行速度根本没有使用本机代码编写的速度快。
对于最常见的内置函数,开发人员将以手写汇编形式编写非常优化的版本。之所以可行,因为ECMAScript规范(点击查看示例)中对这些内置函数的描述非常详细。但是,它有一个很大的缺点:V8针对大量平台和体系结构,这意味着V8开发人员必须为每个体系结构编写和重写所有这些优化的内置函数。随着ECMAScript标准的不断发展和新语言函数的不断标准化,维护所有这些手写程序集变得非常繁琐且容易出错。
遇到此问题后,开发人员开始寻找更好的解决方案。直到TurboFan引入V8才找到解决方案。
CODESTUBASSEMBLER
TurboFan为低层指令带来了跨平台的中间表示(IR),V8团队决定在TurboFan之上构建一个新的前端,他们将其称为CodeStubAssembler。 CodeStubAssembler定义了一种可移植的汇编语言,开发人员可以使用该语言来实现优化的内置函数。最重要的是,可移植汇编语言的跨平台性质意味着开发人员只需编写一次内置函数即可。所有支持的平台和体系结构的实际本机代码都由TurboFan进行编译,你可以在此处阅读有关CSA的更多信息。
尽管这是一个很大的改进,但仍然存在一些问题。使用CodeStubAssembler的语言编写最佳代码需要开发人员积累很多专业知识。即使掌握了所有这些知识,仍然存在很多容易导致安全漏洞的非常规漏洞,这导致V8团队最终编写了一个称为Torque的新组件。
Torque
Torque是基于CodeStubAssembler构建的语言前端,它具有类似TypeScript的语法,强大的类型系统和强大的漏洞检查函数,所有这些使得它成为V8开发人员编写内置函数的理想选择。Torque编译器使用CodeStubAssembler将Torque代码转换为有效的汇编代码,它极大地减少了安全漏洞的数量,你可以在此处阅读更多有关Torque的信息。
漏洞发生的原因
由于Torque仍相对较新,因此仍然需要重新实现大量的CSA代码。其中包括用于处理创建新的FixedArray和FixedDoubleArray对象的CSA代码,它们是V8中的“快”数组(“快”数组具有连续的数组后备存储,而“慢”数组具有基于字典的后备存储)。
漏洞利用
开发人员将CodeStubAssembler :: AllocateFixedArray函数重新实现为两个Torque宏,一个用于FixedArray对象,另一个用于FixedDoubleArray对象:
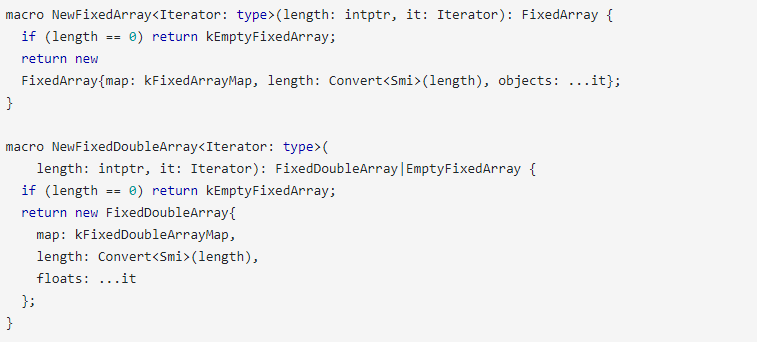
如果将上述函数与CodeStubAssembler :: AllocateFixedArray变体进行比较,则会发现缺少最大长度检查。
NewFixedArray应确保返回的新FixedArray的长度小于FixedArray :: kMaxLength,即0x7fffffd或134217725。
同样,NewFixedDoubleArray应该根据FixedDoubleArray :: kMaxLength(为0x3fffffe或67108862)检查数组的长度。
在我们研究如何使用缺少的长度检查之前,让我们先了解一下Sergey是如何Trigger此漏洞的,因为它不像创建一个大于kMaxLength的新数组那样简单。
V8中的数组
现在,我们需要更多地了解V8中数组的表示方式。
内存中的数组
让我们以数组[1、2、3、4]为例,并在内存中查看它。你可以通过运行带有--allow-natives-syntax标志的V8,创建数组并执行%DebugPrint(array)来获取其地址来实现此目的,使用GDB查看内存中的地址。
在V8中分配数组时,它实际上分配了两个对象。请注意,每个字段的长度为4字节/ 32位:
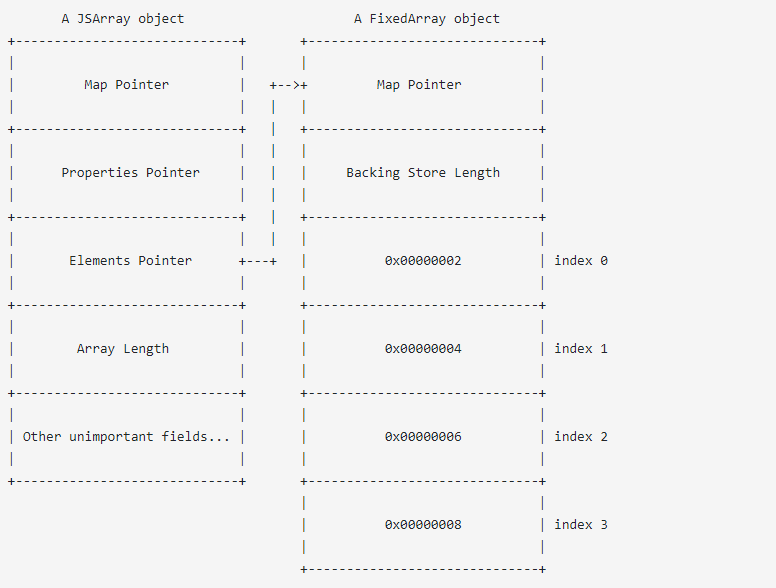
JSArray对象是实际的数组,它包含四个重要字段以及其他一些不重要的字段。
1.映射指针:这决定了数组的“形状”,具体来说,它确定数组存储哪种元素,以及其后备存储对象是什么类型。在这种情况下,我们的数组存储整数,后备存储区为FixedArray。
2.属性指针:指向存储数组可能具有的任何属性的对象。在本例中,数组除了长度以外没有任何属性,长度被内联存储在JSArray对象本身中。
3.元素指针:指向存储数组元素的对象。这也称为后备存储,在本例中,后备存储指向FixedArray对象,稍后会详细介绍。
4.数组长度:这是数组的长度。在研究人员那发布的概念证明中,这是他将长度字段覆盖为0x24242424,然后允许他进行越界读取和写入。
JSArray对象的元素指针指向后备存储,这是一个FixedArray对象,有两个关键的事情要记住:
1.不需要考虑FixedArray中的后备存储长度,你可以将其覆盖为任何值,但仍然无法读取或写入边界。
2.每个索引存储在数组的元素上,内存中值的表示形式取决于数组的“元素种类”,而数组的“元素种类”则取决于原始JSArray对象的映射。在本例中,这些值是一个小的整数,它们是31位整数,其最低位设置为零。 1表示为1 << 1 = 2,2表示为2 << 1 = 4,依此类推。
元素种类
V8中的数组也具有“元素种类”的概念,你可以在此处找到所有元素种类的列表,但所有表的基本思想都是一样的:在V8中每次创建数组时,都会用元素种类标记它,该种类定义了数组包含的元素类型。最常见的三种元素如下:
PACKED_SMI_ELEMENTS:数组被压缩并且仅包含Smis(31位小整数,第32位设置为0)。
PACKED_DOUBLE_ELEMENTS:与上面相同,但为双精度(64位浮点值)。
PACKED_ELEMENTS:与上面相同,但数组仅包含引用。这意味着它可以包含任何类型的元素(整数,双精度数,对象等)。
数组也可以在元素类型之间进行转换,但是转换只能针对更通用的元素类型,而不能针对更具体的元素类型。例如,具有PACKED_SMI_ELEMENTS类型的数组可以转换为HOLEY_SMI_ELEMENTS类型,但不能转换为HOLEY_SMI_ELEMENTS类型,即填充已经有孔的数组中的所有孔都不会导致转换为压缩元素类型的变体。
下面的图表展示了最常见的元素类型的转换格:
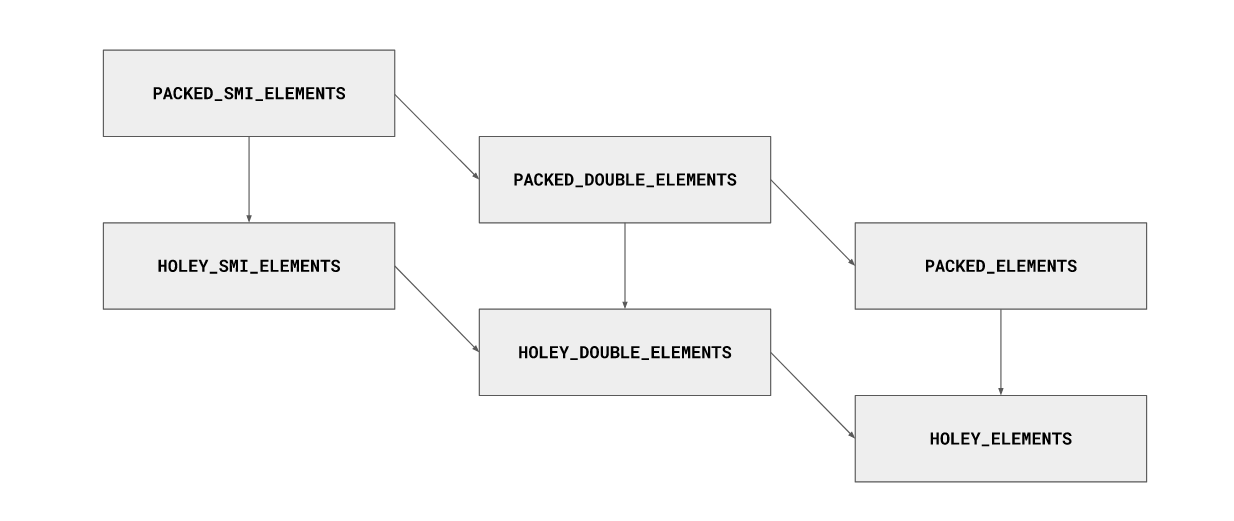
我们实际上只关心与元素类型有关的两件事:
1.SMI_ELEMENTS和DOUBLE_ELEMENTS类型的数组将其元素存储在连续的数组后备存储中,作为它们在内存中的实际表示形式。例如,数组[1.1、1.1、1.1]会将0x3ff199999999999a存储在内存中三个元素的连续数组中(0x3ff199999999999a是1.1的IEEE-754表示形式)。另一方面,PACKED_ELEMENTS类型的数组将存储对HeapNumber对象的三个连续引用,这些引用又包含1.1的IEEE-754表示形式。还有基于字典的备份存储的元素种类,但这不是本文的重点。
2.因为SMI_ELEMENTS和DOUBLE_ELEMENTS类数组的元素大小不同(Smis是31位整数,而双精度是64位浮点型值),所以它们也具有不同的kMaxLength值。
概念验证
Sergey提供了两个概念证明:第一个为我们提供了一个数组,类型为HOLEY_SMI_ELEMENTS类型,长度为FixedArray :: kMaxLength + 3,而第二个为我们提供了一个数组,类型为HOLEY_DOUBLE_ELEMENTS类型,长度为FixedDoubleArray :: kMaxLength + 1。他仅利用第二个概念证明来构造最终的越界访问原语。
两种概念证明都使用Array.prototype.concat来首先获得一个数组,该数组的大小恰好小于相应元素类型的kMaxLength值。完成此操作后,将使用Array.prototype.splice向数组中添加更多元素,这会导致其长度增加到kMaxLength以上。之所以可行,是因为Array.prototype.splice的快路径间接使用了新的Torque函数,如果原始数组不够大,则会分配一个新数组。出于好奇,实现此目的的函数调用链可能如下:

你可能想知道为什么不能创建一个大小刚好低于FixedArray::kMaxLength的大数组并使用它。让我们尝试一下(使用优化的发行版等待的时间会短一些):

这不仅需要花费一些时间,而且还会收到OOM(内存不足)漏洞!发生这种漏洞的原因是,数组分配不会是一次性完成的。对AllocateRawFixedArray的调用很多,每个调用都分配一个稍大的数组。你可以通过在AllocateRawFixedArray上设置断点,然后如上所述分配数组,来在GDB中看到这一点。我不完全确定为什么V8会这样做,但是很多分配都会导致V8很快耗尽内存。
我的另一个想法是改用FixedDoubleArray :: kMaxLength,因为它要小得多(使用优化的发行版):

这确实有效,因为它会返回一个新的HOLEY_DOUBLE_ELEMENTS类型的数组,其长度设置为FixedDoubleArray :: kMaxLength + 1,因此可以使用它代替array .prototype.concat。我相信这样做的原因是因为分配大小为0x3fffffd的数组所需的分配数量足够小,以至于不会不会导致引擎进入OOM。
但是,此方法有两个缺点:分配和填充庞大的数组需要花费大量时间,因此在漏洞利用中并不理想。另一个问题是,尝试在内存受限的环境(例如旧手机)中以这种方式Trigger漏洞,可能会导致引擎运行OOM。
另一方面,Sergey的第一个概念证明在我的计算机上花费了大约2秒钟,并且内存效率很高。以下是具体分析过程。
第一个概念证明
第一个概念证明如下,请确保你使用优化的发行版版本来运行它,否则将需要很长时间才能完成:

让我们一步一步来分析,在[1]的位置,创建了一个大小为0x80000的数组,并使用1填充。这种大小的数组需要分配大量内存,但几乎没有使引擎成为OOM的条件。由于数组最初是空的,因此它得到的是HOLEY_SMI_ELEMENTS类型,即使将其填充为1也会保留该元素的类型。
我们稍后会回到[2],但是在[3]中,使用0xff元素创建了一个新的args数组,每个元素都被设置为在[1]处创建的数组。这使args数组总共为0xff * 0x80000 = 0x7f80000个元素。在[4]处,将另一个大小为0x7fffc的数组压入args数组,这使其总数为0x7f80000 + 0x7fffc = 0x7fffffc个元素,0x7fffffc仅比FixedDoubleArray :: kMaxLength = 0x7fffffd小1。
在[5],Array.prototype.concat.apply将args数组中的每个元素连接到空数组[],你可以在此处阅读有关Function.prototype.apply()如何工作的更多信息,但它实际上将args视为参数数组,并将每个元素连接为最终的数组。我们知道元素总数为0x7fffffc,因此最终数组将具有那么多元素。这种连接发生得比较快(在我的设备上大约需要2秒钟),尽管它比我前面演示的简单地创建数组要快得多。
最后,在[6]处,Array.prototype.splice向该数组追加了4个额外的元素,这意味着其长度现在为0x8000000,即FixedArray :: kMaxLength + 3。
唯一需要说明的是[2],其中将属性添加到原始数组。要了解这一点,你必须首先了解几乎所有V8内置函数的约定是有一个快路径和一个慢路径。在Array.prototype.concat的情况下,采用慢路径的一种简单方法是向要连接的数组添加属,快路径具有以下代码:

可以看到,快路径检查确保最终数组的长度不超过kMaxLength值。由于FixedDoubleArray::kMaxLength是FixedArray::kMaxLength的一半,所以上述概念证明将永远不会通过此检查。随意尝试在不使用array.prop = 1的情况下运行代码;看看会发生什么!
另一方面,慢路径(Slow_ArrayConcat)没有任何长度检查(但是,如果长度超过FixedArray :: kMaxLength,它仍然会崩溃并产生致命的OOM漏洞,因为它调用的其中一个函数仍然会检查长度。这就是为什么研究者会使用慢路径的原因,因为可以绕过快路径中存在的检查。
第二个概念证明(第一部分)
尽管第一个概念证明演示了漏洞,并且可以用于利用(在第二个概念证明中,你只需稍微修改一下trigger函数),但它需要几秒钟才能完成,这可能也不太理想。Sergey选择使用HOLEY_DOUBLE_ELEMENTS类数组。这可能是因为FixedDoubleArray::kMaxLength值明显小于它的FixedArray变体,从而导致更快的Trigger。如果你理解了第一个概念证明,,那么第二个概念证明的第一部分的以下注释版本就很好理解了:

此时,giant_array的长度为0x3ffffff,即FixedDoubleArray :: kMaxLength +1。现在的问题是,我们如何在漏洞利用程序中使用此数组?我们没有任何有用的原语,因此我们需要找到引擎的其他部分,这些部分的代码取决于数组长度不能超过kMaxLength值。
对于大多数研究人员来说,该漏洞本身确实很容易被发现,因为你只需要将函数的新的Torque实现与旧的实现进行比较即可。尽管知道如何利用它,但需要对V8本身有更深入的了解。 Sergey采取的利用途径利用了V8的推测性优化编译器TurboFan,它需要自己引入。
本文翻译自:https://www.elttam.com/blog/simple-bugs-with-complex-exploits/#content