
-
史宾格安全及隐私合规平台3分钟完成一周工作量 更快实现隐私合规
-
IP信誉查询多因子计算,多维度画像
-
智能数据安全网关为企业数据安全治理提供一体化数据安全解决方案
-
4网址安全检测
-
5SMS短信内容安全
-
6百度漏洞扫描
-
7爬虫流量识别
-
8百度AI多人体温检测
-
9工业大脑解决方案
-
10APP安全解决方案
-
11企业人员安全意识解决方案
-
12安全OTA
-
13大模型安全解决方案
-
14安全知识图谱
-
15智能安全运营中心AISOC
热门主题




文心大模型及百度大模型内容安全平台齐获信通院大模型安全认证
2025-07-04 12:06:5918685人阅读
近日,文心大模型与百度大模型内容安全平台——红线大模型双双荣获中国信息通信研究院泰尔认证中心颁发的“大规模预训练模型(文本生成功能)安全认证证书”,且二者的认证级别皆“增强级”的最高级别。

本次认证基于《电信和互联网大规模预训练模型安全评测指标和方法》(TLC 073-2024),此标准由中国信息通信研究院牵头制定,旨在为大规模预训练模型提供安全评测的风险项、指标和方法,系统地评估大模型在59种内容安全风险中的表现。认证分为“基础级”和“增强级”两个层级,适用于大规模预训练模型研发、使用和运营机构,全面客观地衡量大规模预训练模型因自身技术局限或遭滥用和恶意使用而带来的国家安全、公共安全、伦理安全和行业安全风险,可在研发完毕测试、上线前使用以及进行算法备案前使用。其中,百度大模型内容安全平台——红线大模型在网络安全、内容安全、隐私数据安全、模型安全、模型幻觉抑制等诸多评测项目中均表现优异,荣获此次测评中“增强级”的最高级别认证。
大模型作为新质生产力,在千行百业中展现出强大创新潜力。然而,其技术特性带来的安全风险也正引发全球关注。在大模型推理场景中,用户输入内容与模型生成内容中存在的涉政、涉黄、不良价值观、违法犯罪等风险已被人们所熟知。更为严峻的是,OWASP大模型TOP10脆弱性风险揭示了代码攻击、提示词注入、多轮越狱等高级攻击手段的威胁。这些攻击方式利用大模型的语言理解能力,通过精心设计的输入来绕过安全机制,实现恶意目的。此外,针对接口的AIGC盗爬、以消耗算力为目的的资源侵占攻击等,也对模型的稳定运营构成了直接且持续的威胁。这标志着,通用大模型的安全防线必须从内容过滤,延伸至对模型认知过程的深度防护。
基于大模型安全护栏建设的理念,百度大模型内容安全平台正式更名为百度大模型安全护栏。其核心在于通过构建专属的安全红线大模型,大幅降低模型拒答率,并支持风险问题的正向引导和纠偏,为行业提供了一套系统性的大模型安全解决方案。针对大模型推理服务场景存在的模型滥用、算力消耗、隐私泄露、内容违规等风险,百度大模型安全护栏提供接入成本低、一站式的大模型输入、输出安全护栏服务:
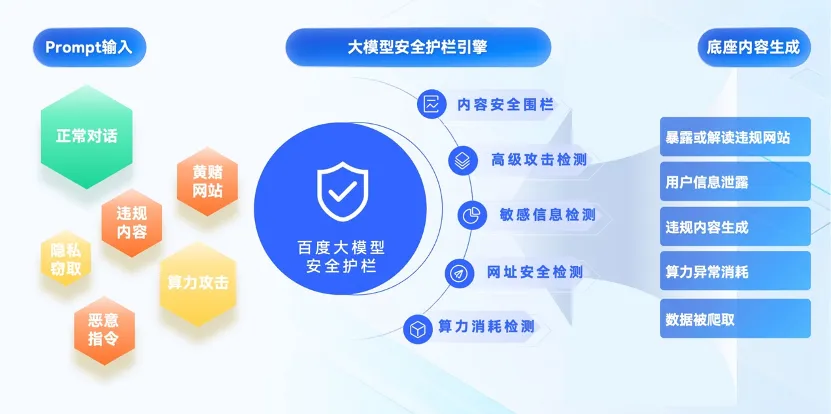
内容安全检测:构建多模态内容安全检测大模型与风险代答模型,精准理解用户意图,并针对风险提问进行错误纠偏与正向引导,在守住内容安全“生命线”基础上,同时又彻底告别“一刀切”式拒答的僵硬模式。
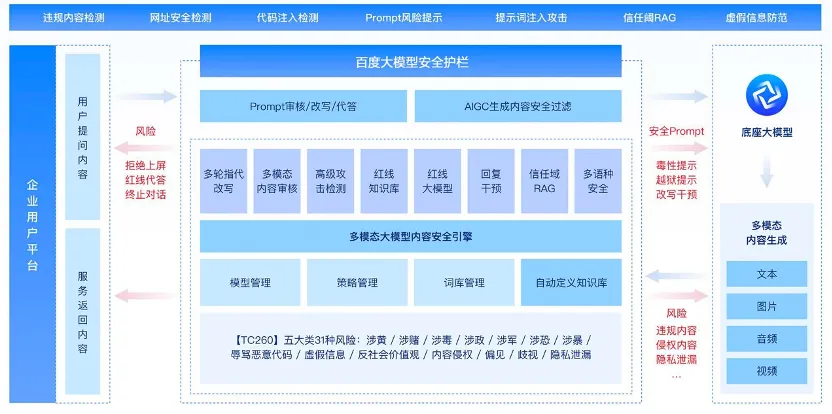
百度大模型安全护栏——功能框架
高级攻击检测:围绕OWASP TOP 10中攻击模式,构建恶意意图与恶意形式检测的大语言模型,支持识别目标劫持、反向抑制、肯定前缀、角色扮演、提示词泄露、混淆编码等多种高级攻击类型。

百度大模型安全护栏——高级攻击检测
敏感信息检测:建设丰富的敏感信息检测能力,包含姓名、身份证号码、手机号码、护照号码、驾驶证号码、住址、邮件地址等数十种个人敏感信息,并提供脱敏能力,避免敏感信息输出导致的舆情风险。
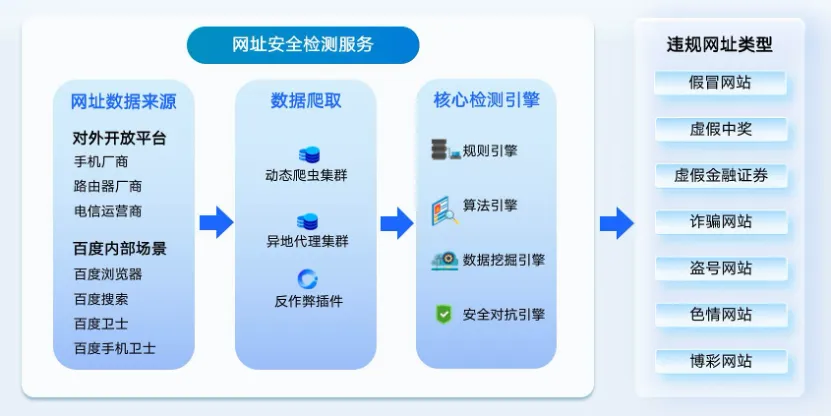
网址安全检测:基于百度丰富的网址黑库数据积累,构建数据爬取与规则检测引擎,提供假冒网站、虚假中奖、虚假金融证券、诈骗网站、色情网站、博彩网站等违规网站检测能力,避免用户通过对话将违规网站投毒到模型中,也避免模型输出对于违规网站信息进行解读的内容。
算力消耗检测:建设完备的规则引擎,针对诱导模型生成长token的提问请求进行监控及拦截,同时支持检测异常IP、异常聚集行为等违规接口调用请求,保障模型资源不被恶意消耗而影响正常用户使用。
百度安全始终积极探索大模型内容安全领域的各种挑战,致力于建设更加安全与健康的大模型发展生态,保障大模型在广泛应用中的安全性和可信度,助力大模型在为企业创造价值的同时,保障个人隐私和信息安全。并提供更加智能、人性化的服务,与产业各方共同努力,携手千行百业建立起覆盖全生命周期的安全防护体系,为开源大模型实现普惠发展、为社会带来更大价值。