
-
史宾格安全及隐私合规平台3分钟完成一周工作量 更快实现隐私合规
-
IP信誉查询多因子计算,多维度画像
-
智能数据安全网关为企业数据安全治理提供一体化数据安全解决方案
-
4网址安全检测
-
5SMS短信内容安全
-
6百度漏洞扫描
-
7爬虫流量识别
-
8百度AI多人体温检测
-
9工业大脑解决方案
-
10APP安全解决方案
-
11企业人员安全意识解决方案
-
12安全OTA
-
13大模型安全解决方案
-
14安全知识图谱
-
15智能安全运营中心AISOC
热门主题




以图搜图遇囧:几个像素就骗过AI?
2019-04-21 22:27:449575人阅读
最近有关图片的争论挺火,我们也来聊聊有关图片的那点事儿。当然,作为靠技术手艺吃饭而非所谓的“版权生意”谋生的,这里要讨论的主题是图片检索安全。

当我们拿到一张图片时,经常会遇到这样的问题:
·手里的这幅尺寸太小,想用作汇报PPT背景的我想要找一张分辨率更高的。
·图片中梅西的凌空抽射太漂亮了,我想要更多类似的照片。
·以及,本着对版权规则的尊重和潜在风险的规避,emmmm,当时我是从哪儿下载到它的呢?
这时,我们大多就要用到图片搜索引擎(Image Search Engine)和它背后的基于内容的图像检索技术(CBIR,Content-Based Image Retrieval),或者说“以图搜图”功能。
以图搜图这并非是个新鲜事物,甚至是一个有着悠久历史的产物。追根溯源,我们可以一直追溯到1992年,日本学者T.Kato发表了一篇名为“Query Visual Example Content based Image Retrieval”的论文,并在文中首次提出了基于内容的图像检索概念。
在这篇论文中,T.Kato构建了一个基于色彩与形状的图像数据库,并提供了一定的检索功能进行实验。此后,基于图像特征提取以实现图像检索的过程以及CBIR这一概念,被应用于包括统计学、模式识别、信号处理和计算机视觉在内的各种研究领域,我们日常使用的搜索功能只是其广泛用途之一。
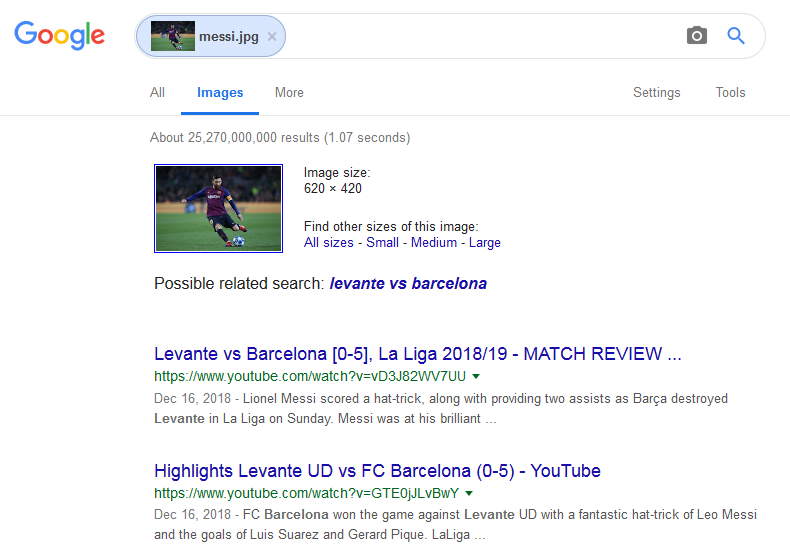
始创者的照片不可考,我们以他被发扬光大的技术产品予以纪念。以Google为例,通过下面两幅事例图,我们可以大致了解以图搜图功能所带来的便利。
事例图1
 事例图2
事例图2
在事例图1中,我们上传一张球星梅西(Messi)射门的照片,Google的按图片搜索功能(Search by Image)不仅识别了图片的尺寸,还准确判断出了图片的来源、名称和事件背景——在这场2018年底举行的18/19赛季西甲联赛第16轮中,梅西领衔的巴塞罗那(Barcelona)以5:0大胜莱万特(Levante),并上演了帽子戏法——显然,如果仅仅通过图片本身,我们很难得知其背后的赛事,甚至连梅西的对手是谁都难以辨识。
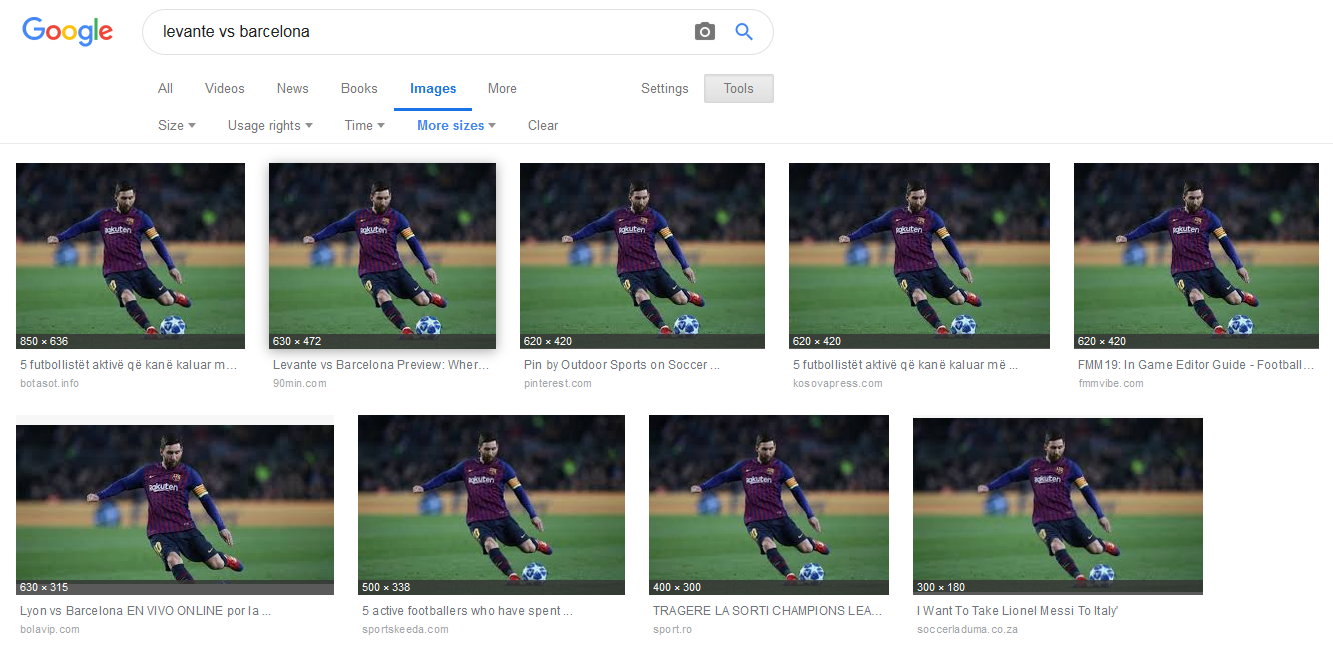
而事例图2则更进一步,按图片搜索功能为我们展示了同一图片更多尺寸的搜索结果。

事实上,不仅是Google的按图片搜索功能,当下众多的类似产品大多也能够实现上述需求。经过逾20年的发展演进,CBIR技术已然日渐成熟并被越来越广泛的应用。但是,它真的足够“聪明”了吗?
在DEF CON CHINA Beta上,来自中国人民大学的弓媛君同学在她的演讲中给出了否定的答案。作为这场顶尖极客大会KeyNote环节中少有的Heroine,她展示了与其导师梁彬教授、黄建军博士关于“欺骗图片搜索引擎”的研究成果,演讲的英文名称为“Fooling Image Search Engine”,这也是2018年DEF CON CHINA Beta精彩演讲系列回顾计划的第三篇。

弓媛君在DEF CON CHINA Beta上的演讲(图片来源于人大新闻网)
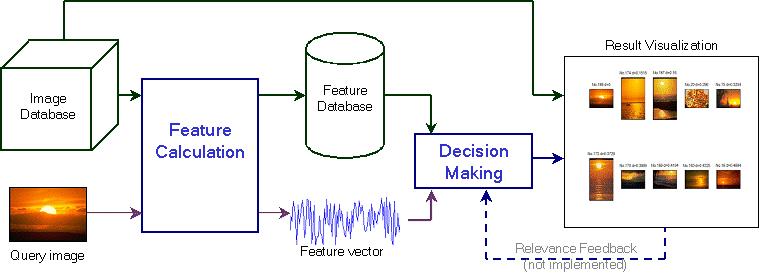
在探讨“欺骗图片搜索引擎”的问题之前,我们首先需要了解“图片搜索引擎”或者说CBIR技术的工作原理。
CBIR技术工作原理图
根据国家自然科学基金资助、由西安电子科技大学发表的“CBIR关键技术研究”论文中的分析和总结,CBIR本质上是一种近似匹配技术,其核心是使用图像的可视特征对图像进行检索,其在特征提取和索引建立方面可由计算机自动完成,避免人工描述的主观性。而用户检索的过程,一般是提供一个样例图像(Queryby Example)或描绘一幅草图(Queryby Sketch),系统抽取该查询图像的特征,然后与数据库中的特征进行比较,并将与查询特征相似的图像返回给用户。
通俗来说,就是CBIR首先要看看你提供的图片有何特征,提炼出一二三四五,然后再从自己的数据库中找出特征类似的图片。而这个数据库,我们姑且可广义理解为搜索引擎能够检索到的整个互联网世界。

CBIR:“这俩一模一样!”
显然,在这一逻辑下,CBIR系统对于图片特征的识别能力——也就是刚刚提到的那个对一二三四五的提炼,是实现图片成功匹配的关键。而如果我们有能力“影响”其对于这些图片特征的判断,那么就会干扰CBIR的识别结果,从而造成返回图片的偏差和错误,甚至存在无法识别的可能性。
这也是弓媛君同学在她的演讲中所提出的“攻击思路”:通过篡改图片某些关键特征点,在保留人眼可“正常”识别的图片视觉语义的情况下,欺骗图片搜索引擎,进而影响检索结果。
基于大多数以图搜图产品采用的是SIFT和SURF两种算法进行特征提取,弓媛君同学和她的团队提出了三种图片扰动方法:
1. 移除特征点(Keypoint Removing Method)
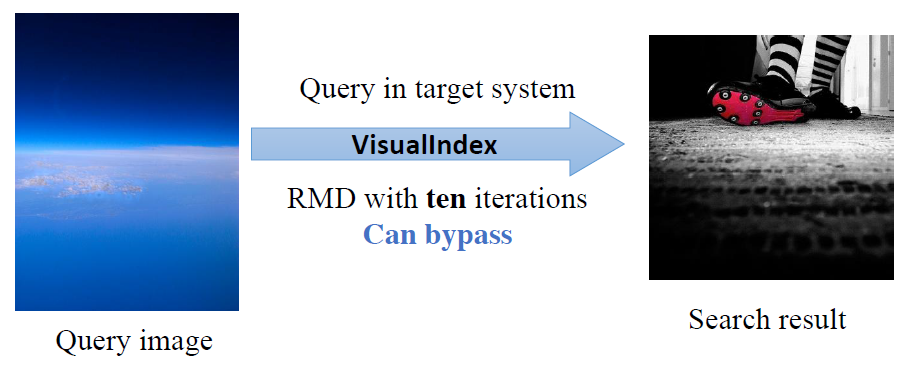
针对SIFT算法,采用已被广泛使用的RMD算法实现特征点移除。
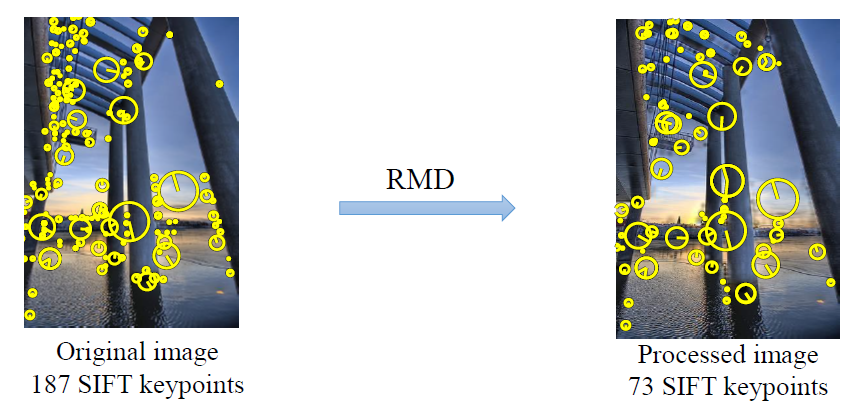
现场演示案例:经过RMD算法的一次迭代,上述图片中的187个特征点被减少为73个
针对SURF算法,采用其自主提出的RMD-SURF算法实现特征点移除。
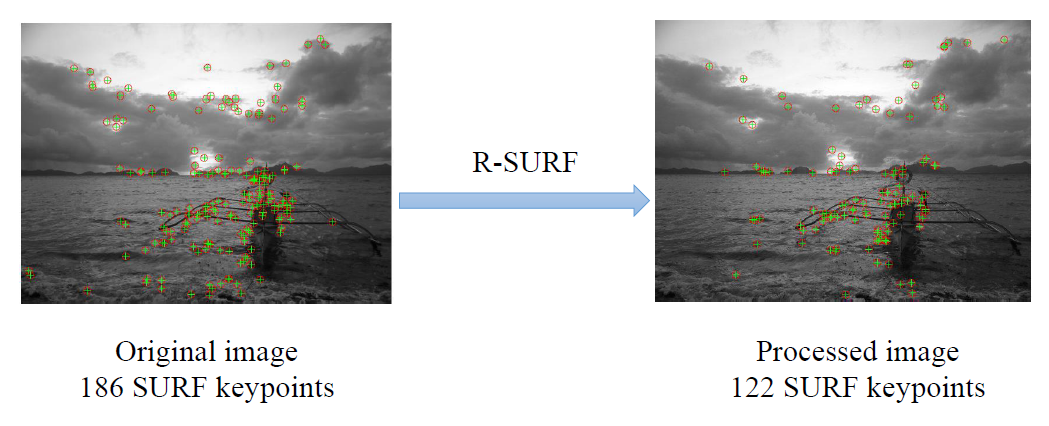
现场演示案例:经过RMD-SURF算法的一次迭代,上述图片中的186个特征点被减少为122个
通过实验,弓媛君同学和她的团队认为,上述方法对于特征点较少的简单图像是有效的,对于复杂图像则需要进行多次迭代才能实现扰动目的,但这会造成视觉语义的明显改变。
2. 注入特征点(Keypoint Injection Method)
有减就有加,既然移除特征点会造成一系列问题,那么注入新的特征点呢?在这里,首先需要回答两个问题:特征点注入到哪里?特征点如何生成?
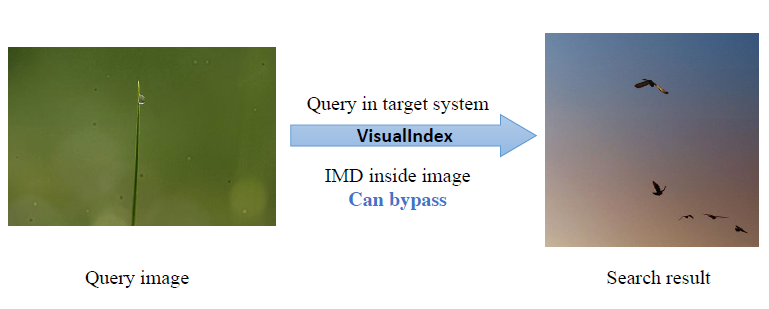
为此,弓媛君同学和她的团队提出了IMD算法(Injection with Minimum Local Distortion),即RMD算法的逆算法。据此,通过向原始图像中注入新的特征点,并在图像边框增加新的特征点单元(Basic Bricks),从而实现对于图像的扰动。
现场演示案例:通过IMD算法对左侧图像注入20个特征点后,搜索结果被干扰
不过,与移除特征点面临的问题类似,注入特征点的方法也仅适用于简单图像,对于复杂图像则无法实现对人眼视觉识别能力的“欺骗”。

现场演示案例:面对复杂图像,IMD算法和Basic Bricks两种注入方法也无法实现干扰
3. 混合扰动(Hybrid)
由此,移除与注入相融合的混合扰动方法便成为了“正确”的攻击姿态。
现场演示案例:RMD移除+IMD注入/RMD移除+Basic Bricks注入,实现搜索结果扰动
在DEF CON CHINA beta“欺骗图片搜索引擎”的主题演讲中,弓媛君同学向我们介绍了基于CBIR图像检索技术下“以图搜图”功能所存在的潜在问题,而“黑白两道”对于AI算法与图像识别的“博弈”并不止于此。
事实上,对“以图搜图”被“欺骗”的研究正在揭示一个在AI时代至关重要的议题——在现阶段,机器学习容易受到对抗样本的攻击,对于诸如移除、注入特征点这类对图像数据的叠加操作所带来的细微扰动,不仅人类难以通过感官辨识,机器学习模型也有可能被“欺骗”并做出错误的判断。
无独有偶,就在今年3月举行的美国RSA大会上,百度安全也展示了在交通领域,“攻击者”如何“欺骗”机器学习算法的实例。

正如上图所示,通过对特征点的“处理”,左侧图片中本该为“停止”的交通标识被AI系统误认为限速45公里(可通行),而右侧图片中铺在地面的旗帜则被误认为一辆汽车。
借助数据篡改或在现实世界中实际的物理干扰,攻击者可让AI系统丧失对于道路标识和其他车辆正确的识别能力,造成严重的安全隐患。而通过对AI模型的破译,攻击者也可以绕过人脸识别系统解锁车辆或直接进行远程控制,实现对车辆的非法接管和对相关隐私信息的窃取。
要知道,包括CBIR在内的众多图像识别系统已开始被广泛应用于自动驾驶、医疗保健、金融认证、工业控制、大数据计算等场景之中,数据安全和“反欺骗能力”的缺位将直接威胁你我的生命财产安全和社会的正常运转。确保AI的安全,打造安全的AI,不仅是AI相关识别技术在各类场景中大范围应用的重要安全前提,也是百度安全始终致力于推动的目标之一。
最后,我们回到这场DEF CON CHINA beta中的精彩演讲本身。从某种意义上讲,弓媛君同学和她的团队所带给现场中外极客大拿们的不仅是单纯的技术分享,还展现了中国顶尖院校在信息安全领域的研究成果和重要作用。
“安全圈子里的男女差别还是有的,你看会场的观众比例就知道了。”正如开篇所言,作为KeyNote环节中、甚至全球极客中少有的Heroine,弓媛君同学在会后接受《南方都市报》采访时也在为女极客们证言,“女生学计算机我觉得还好,主要还是看自己的兴趣点,你不要上来就觉得自己比别人差就好了,实际也没什么差别。”
这周,估计不少人都要进入“权力的游戏”时间。你是否已经发现,故事开始时的Game of Thrones,在这几季中已然成为Game of Queen。而就在几年前,另一部史诗巨著“魔戒”(The Lord Of The Rings)中,洛汗(Rohan)公主伊欧玟(Eowyn)也正是呼喊着“I am No Man”击碎了安格玛巫王(Witch-King of Angmar)“No Man Can Kill Me”的预言。
抛开技术,抛开演讲,抛开攻防,极客世界,正在等待更多Heroine。

最最后,进入DEF CON CHINA 1.0最新进度汇报时间:
2019年5月31日至6月2日,DEF CON CHINA 1.0,锁定北京751D·PARK。
早鸟票现已正式开售,登陆DEF CON CHINA官方网站,直通购票通道。