
-
史宾格安全及隐私合规平台3分钟完成一周工作量 更快实现隐私合规
-
IP信誉查询多因子计算,多维度画像
-
智能数据安全网关为企业数据安全治理提供一体化数据安全解决方案
-
4网址安全检测
-
5SMS短信内容安全
-
6百度漏洞扫描
-
7爬虫流量识别
-
8百度AI多人体温检测
-
9工业大脑解决方案
-
10APP安全解决方案
-
11企业人员安全意识解决方案
-
12安全OTA
-
13大模型安全解决方案
-
14安全知识图谱
-
15智能安全运营中心AISOC
热门主题




百度安全开源大规模图数据库HugeGraph
2018-08-03 15:28:5144832人阅读
图数据库在安全反欺诈、知识图谱、机器学习等诸多领域有着重要的应用,但TitanDB团队被DataStax收购之后,开源图数据库出现了断层。近年来百度安全凭着雄厚的技术实力自主研发了全面支持Apache TinkerPop 3框架和Gremlin图查询语言的大型分布式图数据库HugeGraph,与Neo4j、TitanDB等传统图数据库相比有很多独特的优势。今天我们很高兴的宣布HugeGraph开源,更好的为网络安全、机器学习等社区服务。
HugeGraph主要应用场景是解决百度安全事业部所面对的反欺诈、威胁情报、黑产打击等业务的图数据存储和图建模分析需求,在此基础上逐步扩展及支持了更多的通用图应用。目前HugeGraph在百度安全的应用场景非常多,例如网址安全检测、威胁情报分析、设备关系图谱和数据安全治理等。
HugeGraph拥有良好的读写性能,并且我们根据安全业务场景对图数据库的核心功能(例如批量写入、最短路径、N度关系等)做了重点优化,与常见图数据库Neo4j和TitanDB等相比较,HugeGraph拥有明显的性能优势。
1.GraphDB图数据库
随着社交网络、移动互联网和IOT等新的互联网应用不断涌现,用户、系统和传感器产生的数据呈指数级增长,数据内部依赖和复杂度增加。在应对这些新的趋势时,关系型数据库产生了较多的不适用性,NoSQL(Not Only SQL,不限于SQL)数据库应运而生。
GraphDB图数据库作为一种新型的NoSQL数据库,最近几年广受关注。如图1所示,数据库咨询公司db-engines.com对数据库发展趋势的分析结果表明,图数据库是最近几年发展趋势最明显的数据库类型。
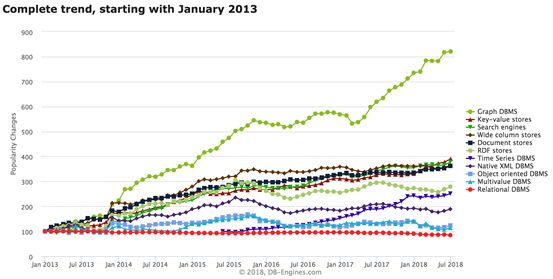
图 1 db-engines.com数据库发展趋势
图数据库是基于图论的数据库,其基本含义是以“图”这种数据结构存储和查询数据。需要注意的是图数据库并不是存储图片的数据库。图数据库的数据模型由顶点(Vertex)、边(Edge)和属性来体现。其基本数据类型可表示为G=(V, E)。其中V={v1, v2, …, vn}表示一系列顶点 , E={ e1, e2, …, en }={{v1, v2 }, {v3, v4 }, {vn-1, vn}}表示一系列边。
2.HugeGraph项目介绍
图数据库所提供的关联分析能力是金融反欺诈、威胁情报、黑产打击和案件溯源等业务所需要的核心能力。百度安全对图数据库的需求非常多,例如金融安全业务希望使用图数据库进行金融反欺诈关联分析、威胁情报业务希望通过图数据库进行黑产研究和情报分析、还有社交关系分析、知识图谱等需求场景。我们也试用过包括TitanDB、Neo4j在内的多款图数据库产品,但由于各种原因无法满足实际业务需求。在此背景下我们基于对安全业务的理解和自身业务需求,设计了HugeGraph图数据库系统。
2.1 HugeGraph的特点
HugeGraph是一款面向分析型,支持批量操作的图数据库系统,它能够与大数据平台无缝集成,有效解决海量图数据的存储、查询和关联分析需求。HugeGraph支持HBase和Cassandra等常见的分布式系统作为其存储引擎来实现水平扩展。HugeGraph可以与Spark GraphX进行链接,借助Spark GraphX图分析算法(如PageRank、Connected Components、Triangle Count等)对HugeGraph的数据进行分析挖掘。
HugeGraph的主要特点包括:
基于TinkerPop 3 API实现,支持Gremlin图查询语言;
拥有完善的周边工具链和相关功能组件,可以满足图数据库开发的基本需求,提供易用高效的使用体验;
具备独立的Schema管理模块,丰富完善的Schema校验机制,确保图数据库中的数据完整性和一致性;
支持数据的备份和还原,可以在不同的后端存储之间转换;
多种ID生成策略应对不同业务场景,拥有完善的索引管理机制,支持多种索引查询操作;
可以实现与Hadoop、Spark、HBase、ES等大数据系统集成,支持多种Bulk Load操作,实现海量数据快速插入;
除上述特定之外,HugeGraph还针对图数据库的高频应用(例如:ShortestPath、k-out、k-neighbor等)做了特定性能优化,并且为用户提供更为高效的使用体验。
2.2 HugeGraph的系统架构
作为一款通用的图数据库产品,HugeGraph需具备图数据的基本功能。如图2所示,HugeGraph的系统架构主要包括存储层、计算层和用户接口层三个功能层次。
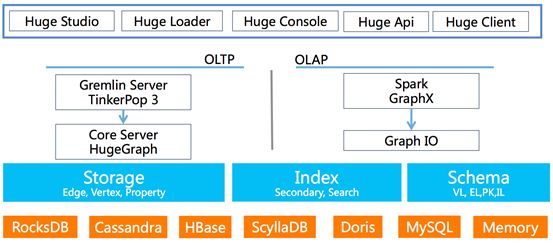
图2 HugeGraph的系统架构
HugeGraph的存储层包括图数据(顶点、边和属性等)存储、索引数据存储和Schema元数据存储。HugeGraph后端存储会采用插件化方案,目前已经支持RocksDB、Cassandra、ScyllaDB、HBase、Doris(原Baidu Palo)和MySQL等,后续会适配更多的后端存储系统。
HugeGraph的计算层包括OLTP和OLAP两种类型。其中HugeGraph重点实现了OLTP核心功能,而OLAP部分功能需要和Spark GraphX相结合完成。
HugeGraph提供了多种接口方式,用户可以根据自己的业务需求和喜好,选择相应的接口来操作HugeGraph,具体包括:
HugeStudio(基于Web的IDE可视化编辑环境)
HugeLoader(数据导入工具)
HugeConsole(基于命令行的Gremlin接口)
HugeApi(基于Rest的Api接口)
HugeClient(基于Java的客户端驱动程序)
2.3 HugeGraph的性能指标
HugeGraph具有良好的读写性能,可以胜任多种图应用场景。我们使用图数据库Benchmark测试工具对HugeGraph进行性能测试,并对比了HugeGraph、TitanDB和Neo4j等常见的图数据库,以下是HugeGraph的基本性能数据。
2.3.1 批量写入
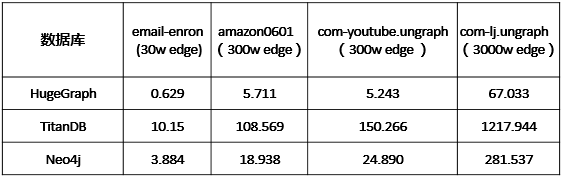
我们在4组开源数据集分别对HugeGraph、TitanDB和Neo4j进行批量写入性能测试,测试结果如表1所示。HugeGraph采用RocksDB存储引擎时插入amazon0601数据集的300万条边耗时为5.711秒,平均每秒可完成50万条边插入。性能数据分析来看HugeGraph的批量插入性能明显优于Neo4j和TitanDB。
表1HugeGraph批量插入的性能
2.3.2 最短路径
我们使用同样的4组数据集分别测试HugeGraph、TitanDB和Neo4j三款图数据库在最短路径查找的性能。测试方式是从第一个顶点出发到达随机选择的100个顶点的最短路径,测试数据如表2所示。HugeGraph对最短路径求解采用双向广度优先算法进行优化,其最短路径查询性能明显高于TitanDB,与Neo4j处于同一水平,小数据量情况下HugeGraph略胜于Neo4j。
表2HugeGraph最短路径查询性能

2.3.3 N度关系
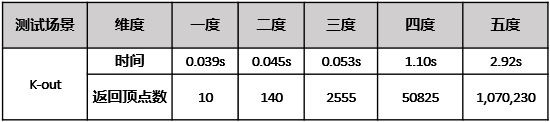
HugeGraph针对“好友的好友”这类常见“N度关系”查询也进行了特定优化。我们将N度关系查询分为K-neighbor和K-out两种模式。例如要查询3度关系(即好友的好友的好友),K-neighbor则返回3度之内的所有节点,K-out仅返回3度关系节点。关于K-out的测试数据如表3所示,HugeGraph可以3秒内完成amazon0601的开源数据集(40万节点和338万的边)的5度关系查询。
表3HugeGraph K-out性能
关于HugeGraph的更多性能测试数据,请查询见官方文档:
(https://hugegraph.github.io/hugegraph-doc/performance/hugegraph-benchmark-0.5.6.html)
具体的测试方法和逻辑请参考:
HugeGraph-Benchmark(https://github.com/hugegraph/graphdb-benchmarks)
3.HugeGraph体系结构
HugeGraph已经在GitHub上开源,项目地址是https://github.com/hugegraph。HugeGraph包含了10多个关联子项目,其中包括:
1.HugeGraph
HugeGraph子项目是HugeGraph项目的核心部分,包含Core、Backend、API等子模块。该模块实现了TinkerPop框架接口,并提供Schema元数据管理,事务、缓存和序列化等功能。HugeGraph可以支持多种后端存储系统,用户可以根据实现需求灵活选择;另外通过内置的HugeGraph-Server(简称为HugeServer)对外提供Restful API,该接口也可以接收Gremlin查询。
2.HugeGraph-Client
简称为HugeClient,提供了Rest API的客户端,用于连接HugeServer,目前实现Java版,其他语言用户可自行封装实现;
3.HugeGraph-Loader:
简称为HugeLoader,是基于HugeClient的数据导入工具,可将普通JSON、CSV等文本数据转化为图的顶点和边并快速插入图数据库中;
4.HugeGraph-Studio
简称为HugeStudio,是HugeGraph的Web可视化工具,可用于执行Gremlin语句并将图的链接关系通过Web可视化呈现。
HugeGraph各组件之间的关系如图3所示:
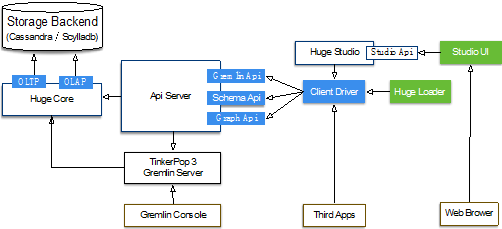
图3 HugeGraph各组关系图
4.HugeGraph的应用场景
百度安全每天需要处理大量的日志数据,并对数据进行挖掘分析以识别各种安全问题,HugeGraph为安全业务提供关联分析能力。HugeGraph在百度安全内部的应用场景非常广泛,包括网址安全检测、设备关系图谱和数据安全治理等。
4.1 网址安全检测
搜索是百度的核心业务之一,为保证用户访问的网站是安全的,我们需要对搜索引擎的每一个网页进行安全检测,以防止用户通过搜索引擎入口访问恶意网站。在网址安全检测项目中,我们使用HugeGraph存储网站的基本信息包括域名Whois、IP和外链等,安全分析人员可以方便分析站点之间的关系。另外从链接关系入手,结合PageRank等图挖掘算法可以发现网站链接异常行为,识别网络黑产业。据此我们发现了黑产利用运营商漏洞进行用户隐私窃取的行为,也发现了虚拟点击和非法推广等非法行为,切实维护了网民的权益。
4.2 设备关系图谱
关联分析是威胁情报、黑产打击和案件溯源等业务所需要的核心能力,构建设备关系图谱,提供设备关联分析能力是黑产对抗所需要的核心能力。我们使用HugeGraph存储手机号码、帐号ID、设备指纹等设备信息,通过ID-Mapping和关联分析,精确识别黑产作弊设备,并为业务风控提供细粒度的反作弊策略。
4.3 威胁情报分析
在威胁情报处理方面,利用HugeGraph将恶意攻击记录、恶意IP、恶意域名、Whois信息、漏洞库、文件、邮件地址、杀软检测、开源情报等信息结合构建威胁情报关系网,为风控业务和安全应急响应中心提供服务。另外在伪造设备识别、群控挖掘、自然人识别等方面,HugeGraph也发挥了很大的作用。
4.4 安全数据治理
在安全领域之外之外,图数据库也可以应用在知识图谱、企业图谱、推荐系统、社交网络、IT运维等多种场景中应用。目前我们也将HugeGraph应用到安全数据治理中项目中。我们将数据资产作为图数据库的顶点,将对数据资产的ETL处理作为图数据库的边,通过顶点和边的关联关系分析数据血缘,并在此基础上实施安全数据治理策略。

图4 HugeGraph在数据治理中的应用
5.开源有你
HugeGraph项目及其子项目选择使用ApacheLicense V2开源协议下开源。Apache License V2开源协议是一款给予使用者很大自由的协议,使用者可以在需要的时候修改HugeGraph的代码来满足其业务需要并作为开源发布,也可以集成到其商业产品发布或销售。我们通过开源的方式发布HugeGraph希望有更多的人使用HugeGraph来解决实际业务问题,共同推动图数据库的进一步发展。同时也非常欢迎开源社区、工业界、学术界的用户支持和贡献。支持HugeGraph的途径有很多,例如:
1.下载并试用HugeGraph,给我们反馈使用感受和改进建议
2.参与贡献HugeGraph的开发流程、完善相关文档、帮助解答常见问题等
3.参与贡献HugeGraph维护的核心工具代码,例如HugeCore、 HugeLoader、HugeStudio、HugeClient、HugeSpark等
4. 贡献完善HugeGraph周边生态工具,例如多语言客户端驱动程序Python Client Driver等
如果你对HugeGraph图数据库感兴趣,欢迎大家来到HugeGraph在GitHub的社区
(https://github.com/hugegraph)
参与社区讨论或贡献代码。
