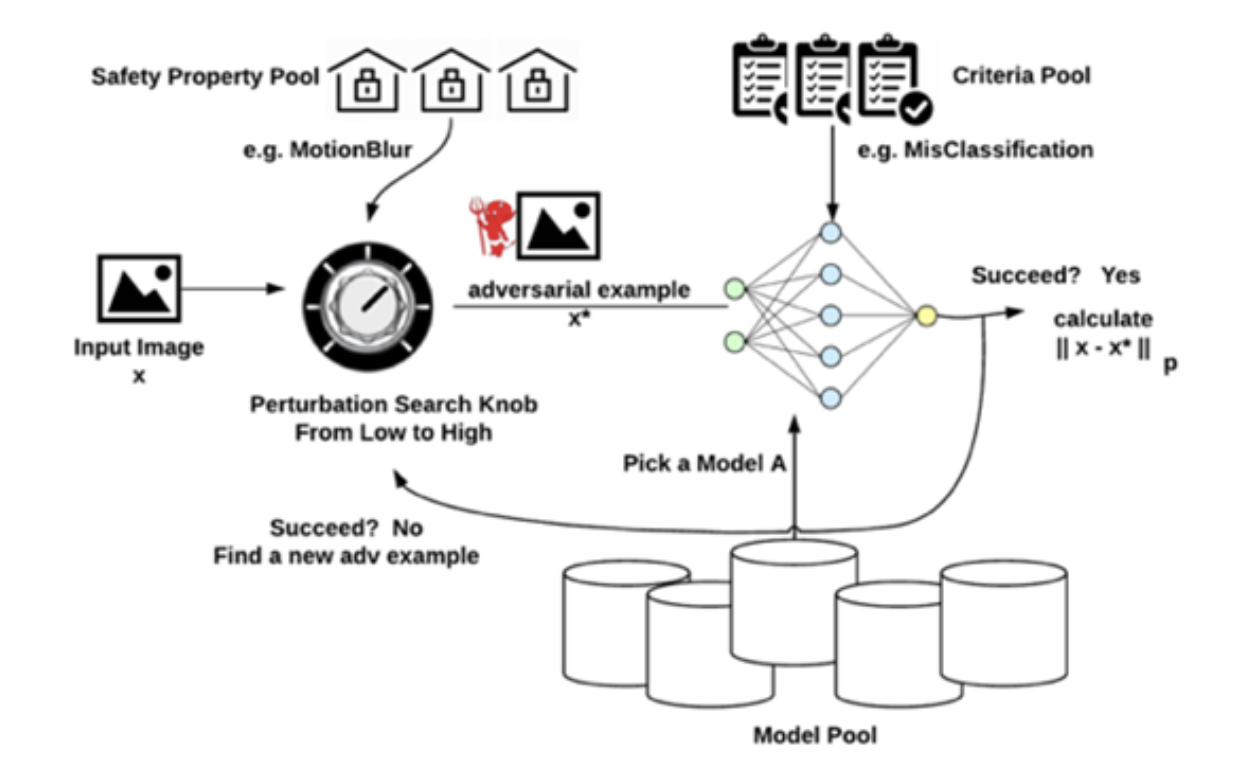
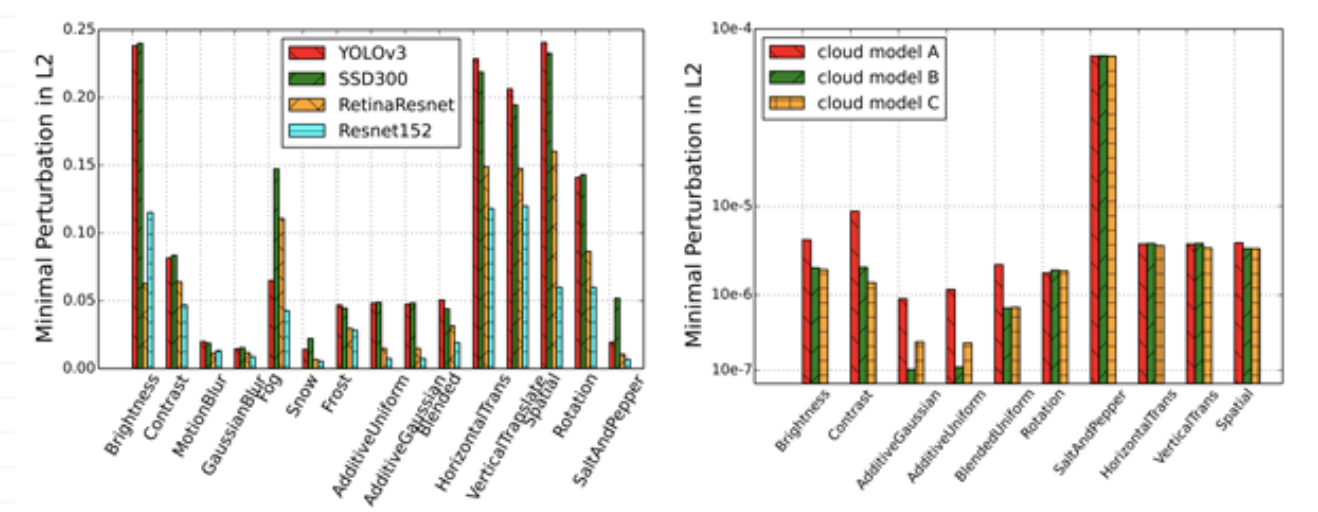
6月29日-7月2日在西班牙召开的 International Conference on Dependable Systems and Networks (DSN 2020)会议上, 来自百度安全对于深度神经网络(DNN)模型安全性的研究Quantifying DNN Model Robustness to theReal-World Threats成功入选。在该文章中,百度安全研究员们建立了一套衡量深度神经网络面对真实存在于物理世界威胁时鲁棒性的标准化框架。百度安全希望通过这个研究呼吁业内将人工智能模型的面对威胁,特别是面对物理世界中的威胁时的表现纳入衡量模型的标准,携手工业界、学术界共同探索与建设安全的AI时代。DSN是可信系统和网络的国际会议,是国际顶尖的计算机会议之一,具有广泛的影响力。DSN2020国际会议,共有285篇论文投稿,录用48篇,录取率仅为16.8%。DSN率先提出了系统可靠性和安全性研究之间的融合,并以其独具一格的眼光聚焦于意外和恶意网络攻击,使其成为引领增强当今各种计算系统和网络的鲁棒性最负盛名的国际会议,为百度安全分享在AI鲁棒性研究提供了一个完美的舞台。深度学习模型容易受到对抗样本的恶意攻击,这在业内已不是新鲜事。对图像数据添加人类难以通过感官辨识到的细微扰动,便可“欺骗”模型,指鹿为马,甚至无中生有。为实施此类攻击,攻击者往往需要提取了解模型结构模型的架构、参数,继而利用特定算法针对性的生成“对抗样本”,诱导模型做出错误的,甚至攻击者预设的判别结果。然而在面对应用在安全攸关场景下的商业模型(例如,人脸识别、语音识别、无人驾驶等领域)中,很少有机会让攻击者掌握如此多的信息。当下以Google、Amazon为代表的国内外知名科技公司将云计算的运作模式与人工智能深度融合,将人工智能技术作为一种云服务(AIaaS,人工智能即服务)提供给用户和合作伙伴,除Amazon等少数公司会告知模型算法,绝大多数公司仅向用户反馈调用结果。模型信息以及攻击者攻击变现手段的缺失,此类恶意攻击尚未在现实业务中大量出现。但这并不意味着这些商业模型就固若金汤了。百度安全团队在DSN 2020上带来的最新研究成果表明,真实世界的环境因素对输入数据正常扰动(例如:亮度、对比度变化,摄像头的抖动等等)就足以对深度学习模型的分类或预测结果产生不一致。更为要命的是此类威胁在非对抗场景中与生俱来。而业内对此类威胁重视程度并不足,目前缺乏对此类威胁的合理定义,并且苦于无法有效地评估深度学习模型鲁棒性。如果持续忽略此类威胁,不仅会导致严重的安全事故,也会破坏整个人工智能生态应用的进程。如果说对抗样本的发现,将传统安全产业框架延伸至机器学习模型算法安全性的范畴,那么物理世界安全属性扰动带来的威胁,则令这个问题更加严峻和复杂。这意味着现有模型在不存在恶意攻击者情况下就可能自乱阵脚,AI系统在特定环境下,例如自动驾驶在雨雪天气,颠簸路面将丧失对城市交通、道路标识及车辆正确的识别能力。此类威胁还可延伸至金融认证、安全监控等领域,蕴含巨大的安全风险。建立有效的模型鲁棒性评估机制是打造真正安全可行的AI系统必不可少的基石。百度安全团队中的Zhenyu Zhong、Zhisheng Hu、XiaoweiChen博士创新性的提供了一个模型鲁棒性评估量化框架,如图2所示。首先基于现实世界的正常扰动定义了可能出现威胁的五大安全属性,分别是光照,空间变换,模糊,噪声和天气变化。并且针对不同的模型任务场景,制定了不同的评估标准,如非定向分类错误、目标类别错误分类到评估者设定的类别等标准。对于不同安全属性扰动带来的威胁,该框架采用了图像领域中广为接受的最小扰动的Lp-norm来量化威胁严重性以及模型鲁棒性。百度安全团队在现场展示了不同学习任务模型 - - 包含13个开源图像分类模型、3个SOTA目标检测模型、3个商用云端黑盒模型,在面对不同安全属性下带来的威胁,以及不同评估标准下的鲁棒性测评。并且展示了同类型学习下,不同模型鲁棒性的横向比较。评测结果表明,物理世界威胁不但普遍存在,而且较小的扰动就足以触发。无论是目标检测模型还是云端黑盒模型,在各个安全属性扰动下,都会被成功欺骗。例如图3中所示,由于摄像头抖动带来的极小的motion blur就足以使实验中的3个目标检测模型产生误判。而这些目标检测模型常用于自动驾驶中。同样用于不良内容过滤的云端模型,添加轻微的噪声便足以绕过。百度安全研究员还与参会学者一同探讨了百度安全针对物理世界威胁解决思路,包括针对特定安全场景选取不同模型框架、对抗训练强化模型提高深度学习模型鲁棒性等途径。此外,百度安全始终倡导通过新一代技术研发与开源,此文中的鲁棒性评估量化框架已与百度安全perceptron robustness benchmarking dataset一同应用于百度深度学习开源平台PaddlePaddle及当下主流深度学习平台,可高效地评估模型面对物理世界威胁的特征统计,同时也支持使用最新的生成方法构造恶意对抗样本数据集用于攻击全新的AI应用、加固业务AI模型,为模型安全性研究和应用提供重要的支持。https://www.youtube.com/watch?v=7t1WCn3gPd4