
-
史宾格安全及隐私合规平台3分钟完成一周工作量 更快实现隐私合规
-
IP信誉查询多因子计算,多维度画像
-
智能数据安全网关为企业数据安全治理提供一体化数据安全解决方案
-
4网址安全检测
-
5SMS短信内容安全
-
6百度漏洞扫描
-
7爬虫流量识别
-
8百度AI多人体温检测
-
9工业大脑解决方案
-
10APP安全解决方案
-
11企业人员安全意识解决方案
-
12安全OTA
-
13大模型安全解决方案
-
14安全知识图谱
-
15智能安全运营中心AISOC
热门主题




学点算法搞安全之HMM(下篇)
2017-12-15 15:55:5712804人阅读
前言
上篇我们介绍了HMM的基本原理以及常见的基于参数的异常检测实现,这次我们换个思路,把机器当一个刚入行的白帽子,我们训练他学会XSS的攻击语法,然后再让机器从访问日志中寻找符合攻击语法的疑似攻击日志。
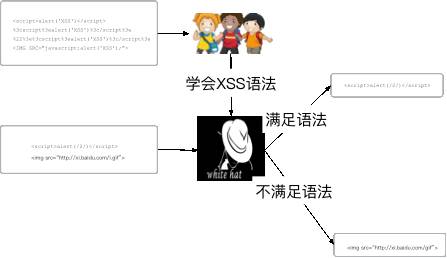
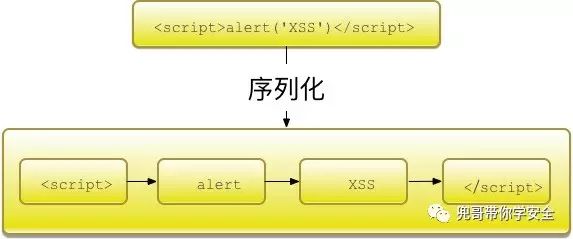
通过词法分割,可以把攻击载荷序列化成观察序列,举例如下:
词集/词袋模型
词集和词袋模型是机器学习中非常常用的一个数据处理模型,它们用于特征化字符串型数据。一般思路是将样本分词后,统计每个词的频率,即词频,根据需要选择全部或者部分词作为哈希表键值,并依次对该哈希表编号,这样就可以使用该哈希表对字符串进行编码。
词集模型:单词构成的集合,集合自然每个元素都只有一个,也即词集中的每个单词都只有一个
词袋模型:如果一个单词在文档中出现不止一次,并统计其出现的次数
本章使用词集模型即可。
假设存在如下数据集合:
dataset = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
首先生成词汇表:
vocabSet = set()
for doc in dataset:
vocabSet |= set(doc)
vocabList = list(vocabSet)
根据词汇表生成词集:
# 词集模型
SOW = []
for doc in dataset:
vec = [0]*len(vocabList)
for i, word in enumerate(vocabList):
if word in doc:
vec[i] = 1
SOW.append(doc)
简化后的词集模型的核心代码如下:
fredist = nltk.FreqDist(tokens_list) # 单文件词频
keys=fredist.keys()
keys=keys[:max] #只提取前N个频发使用的单词 其余泛化成0
for localkey in keys: # 获取统计后的不重复词集
if localkey in wordbag.keys(): # 判断该词是否已在词集中
continue
else:
wordbag[localkey] = index_wordbag
index_wordbag += 1
数据处理与特征提取
常见的XSS攻击载荷列举如下:
<script>alert('XSS')</script>
%3cscript%3ealert('XSS')%3c/script%3e
%22%3e%3cscript%3ealert('XSS')%3c/script%3e
<IMG SRC="javascript:alert('XSS');">
<IMG SRC=javascript:alert("XSS")>
<IMG SRC=javascript:alert('XSS')>
<img src=xss onerror=alert(1)>
<IMG """><SCRIPT>alert("XSS")</SCRIPT>">
<IMG SRC=javascript:alert(String.fromCharCode(88,83,83))>
<IMG SRC="jav ascript:alert('XSS');">
<IMG SRC="jav ascript:alert('XSS');">
<BODY BACKGROUND="javascript:alert('XSS')">
<BODY ONLOAD=alert('XSS')>
需要支持的词法切分原则为:
单双引号包含的内容
'XSS'
http/https链接
http://xi.baidu.com/xss.js
<>标签
<script>
<>标签开头
<BODY
属性标签
ONLOAD=
<>标签结尾
>
函数体
"javascript:alert('XSS');"
字符数字标量
代码实现举例如下:
tokens_pattern = r'''(?x)
"[^"]+"
|http://\S+
|</\w+>
|<\w+>
|<\w+
|\w+=
|>
|\w+\([^<]+\) #函数 比如alert(String.fromCharCode(88,83,83))
|\w+
'''
words=nltk.regexp_tokenize(line, tokens_pattern)
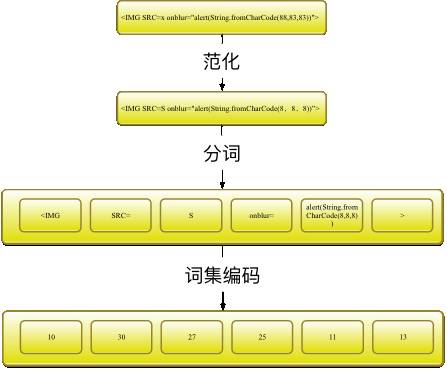
另外,为了减少向量空间,需要把数字和字符以及超链接范化,具体原则为:
#数字常量替换成8
line, number = re.subn(r'\d+', "8", line)
#ulr日换成http://u
line, number = re.subn(r'(http|https)://[a-zA-Z0-9\.@&/#!#\?]+', "http://u", line)
#干掉注释
line, number = re.subn(r'\/\*.?\*\/', "", line)
范化后分词效果示例为:
#原始参数值:"><img src=x onerror=prompt(0)>)
#分词后:
['>', '<img', 'src=', 'x', 'onerror=', 'prompt(8)', '>']
#原始参数值:<iframe src="x-javascript:alert(document.domain);"></iframe>)
#分词后:
['<iframe', 'src=', '"x-javascript:alert(document.domain);"', '>', '</iframe>']
#原始参数值:<marquee><h1>XSS by xss</h1></marquee> )
#分词后:
['<marquee>', '<h8>', 'XSS', 'by', 'xss', '</h8>', '</marquee>']
#原始参数值:<script>-=alert;-(1)</script> "onmouseover="confirm(document.domain);"" </script>)
#分词后:
['<script>', 'alert', '8', '</script>', '"onmouseover="', 'confirm(document.domain)', '</script>']
#原始参数值:<script>alert(2)</script> "><img src=x onerror=prompt(document.domain)>)
#分词后:
['<script>', 'alert(8)', '</script>', '>', '<img', 'src=', 'x', 'onerror=', 'prompt(document.domain)', '>']
结合词集模型,完整的流程举例如下:
训练模型
将范化后的向量X以及对应的长度矩阵X_lens输入即可,需要X_lens的原因是参数样本的长度可能不一致,所以需要单独输入。
remodel = hmm.GaussianHMM(n_components=3, covariance_type="full", n_iter=100)
remodel.fit(X,X_lens)
验证模型
整个系统运行过程如下:
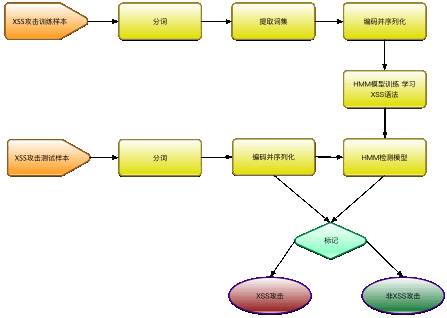
验证阶段利用训练出来的HMM模型,输入观察序列获取概率,从而判断观察序列的合法性,训练样本是1000条典型的XSS攻击日志,通过分词、计算词集,提炼出200个特征,全部样本就用这200个特征进行编码并序列化,使用20000条正常日志和20000条XSS攻击识别(类似JSFUCK这类编码的暂时不支持),准确率达到90%以上,其中验证环节的核心代码如下:
with open(filename) as f:
for line in f:
line = line.strip('\n')
line = urllib.unquote(line)
h = HTMLParser.HTMLParser()
line = h.unescape(line)
if len(line) >= MIN_LEN:
line, number = re.subn(r'\d+', "8", line)
line, number = re.subn(r'(http|https)://[a-zA-Z0-9\.@&/#!#\?:]+', "http://u", line)
line, number = re.subn(r'\/\*.?\*\/', "", line)
words = do_str(line)
vers = []
for word in words:
if word in wordbag.keys():
vers.append([wordbag[word]])
else:
vers.append([-1])
np_vers = np.array(vers)
pro = remodel.score(np_vers)
if pro >= T:
print "SCORE:(%d) XSS_URL:(%s) " % (pro,line)
本文来自兜哥带你学安全,原文链接:兜哥带你学安全
文章图片来源于网络,如有侵权请联系我们