
-
史宾格安全及隐私合规平台3分钟完成一周工作量 更快实现隐私合规
-
IP信誉查询多因子计算,多维度画像
-
智能数据安全网关为企业数据安全治理提供一体化数据安全解决方案
-
4网址安全检测
-
5SMS短信内容安全
-
6百度漏洞扫描
-
7爬虫流量识别
-
8百度AI多人体温检测
-
9工业大脑解决方案
-
10APP安全解决方案
-
11企业人员安全意识解决方案
-
12安全OTA
-
13大模型安全解决方案
-
14安全知识图谱
-
15智能安全运营中心AISOC
热门主题




企业应用指纹平台框架实践
2018-09-11 15:02:4615407人阅读
前言
当外界爆出0day或者高危通用漏洞时,安全工程师需要排查所有受影响产品和业务线。如果缺乏一种快速、统一的查询方式,将导致安全工程师浪费大量时间在受影响资产排查上,也将极大地降低安全应急的效率。应用指纹平台收集和展示web和主机应用相关指纹信息,提供快速的指纹检索能力,能够极大地提高安全应急速度,从而最大程度保障企业安全。
指纹的识别方式
应用的指纹,可以分为三类:
web指纹:传统的web应用信息,包括web应用、框架、服务器等信息。
主机指纹:主机上的服务和类库相关信息,以及端口和banner的信息。
代码指纹:代码中包含的web组件或者类库的信息。
0x01 web指纹识别
企业的web指纹识别既有外界常见的黑盒扫描方式的识别,也有运用主机agent、公司代码库等,从源码级别执行的白盒指纹识别,两者结合可以最大程度保证企业web相关指纹信息的全面采集:
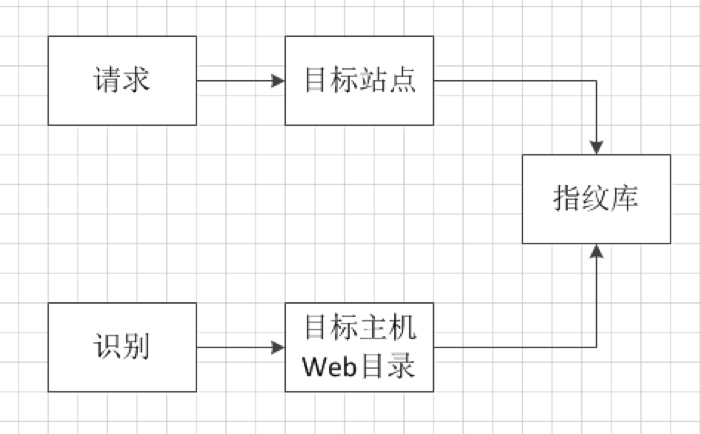
黑盒指纹识别,原理类似于黑盒扫描服务。在企业内部,扫描来源为:域名 + URL。通过前期收集业务线URL,可以避免使用爬虫,在保证扫描效果的情况下降低性能开销和提高效率。
黑盒识别的主要方式包括:
响应体中包含特定字符串,例如phpBB Group
响应头中包含特定字符串,例如Set-Cookie: phpbb
特殊url路径中包含特定字符串,例如/wp-admin
存在特殊文件,例如wordpress/wp-includes/wlwmanifest.xml
{
"name": "discuz",
"scope": "10",
"object": "response_body",
"position": "",
"value": {
"body": {
"match": ["<meta\\s+name=['\"](generator|author)['\"]\\s+content=['\"]Discuz![^'\"]*['\"][^>]*/?>"],
"nomatch": []
},
"headers": {},
"url": {},
"status_code": {}},
"rank": "9"
}
其中object代表规则类型,包含response_head(响应头)、response_body(响应体)、special_page(特殊页面)和url(特定url);position,仅当object为特殊页面时,用于指定页面具体url(不包含host);value则是匹配正则,不同字段匹配不同位置返回数据,而status_code则可以指定响应码,与前面几种类型结合,达到排除某些误报。针对每条规则,除了扫描当前域名外,还需要从url库中提取一定数量包含当前域名的url,然后根据这些特定的url返回数据进行匹配,scope即用于指定提取url数量。
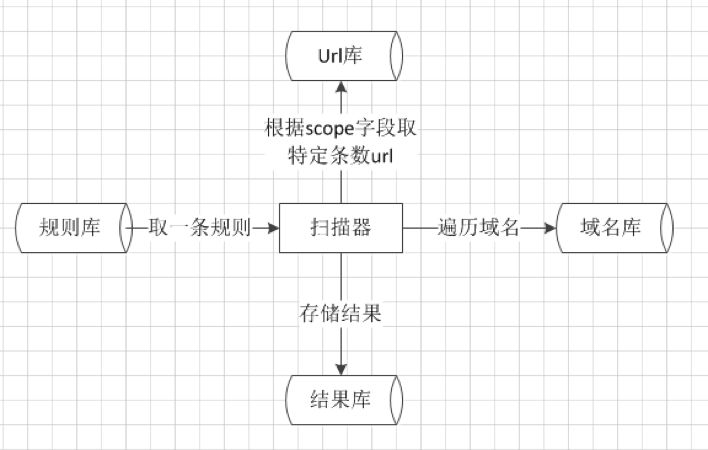
为了覆盖范围更加广泛,可以先对域名库中的url提取web目录,例如http://xxx.com/test/test1/test2.html,可以提取出xxx.com/test/和xxx.com/test/test1两个子域名,加入到域名库中后,可以对一些子目录下包含单独web应用的情况进行fuzz。
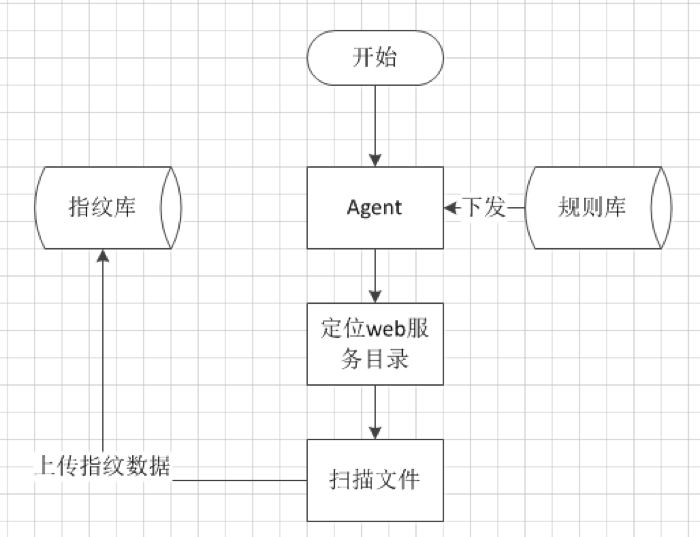
白盒web指纹,是通过部署在企业服务器上的agent对线上web目录中文件进行信息提取从而识别线上web服务,能够较好的对web指纹进行补充,解决黑盒指纹无法覆盖的一些组件,例如开发语言、Java框架以及一些PHP框架。识别规则相对于黑盒来说,略有区别:
{
"name":"DeDeCMS",
"ruletype":"fileDir",
"filePath":"/dedeajax2\.js$,/dedetag\.class\.php$,/dedesql\.class\.php$",
"fileContentPattern": "",
"verPattern": "",
"minmatch": 3,
"verIndex": 1
}
识别规则包含文件路径规则(fileDir)和文件内容规则(fileContent),通过指定urletype从而决定识别filePath中的文件名还是文件内容;同时由于第三方web组件通常会将版本号放置在文件中,例如pom.xml或者version.php等,因此我们可以在verPattern中指定版本正则,例如识别ThikPHP的版本正则为“\s*define\(\'THINK_VERSION\',\s*\'(\d+(?:\.\d+)*)\'\)\s*”,verIndex可以指定匹配的版本号属于哪一个group,其中group[0]为整个版本匹配字符串,group[1]即为版本字符串。识别流程为:
0x02 主机层面指纹识别
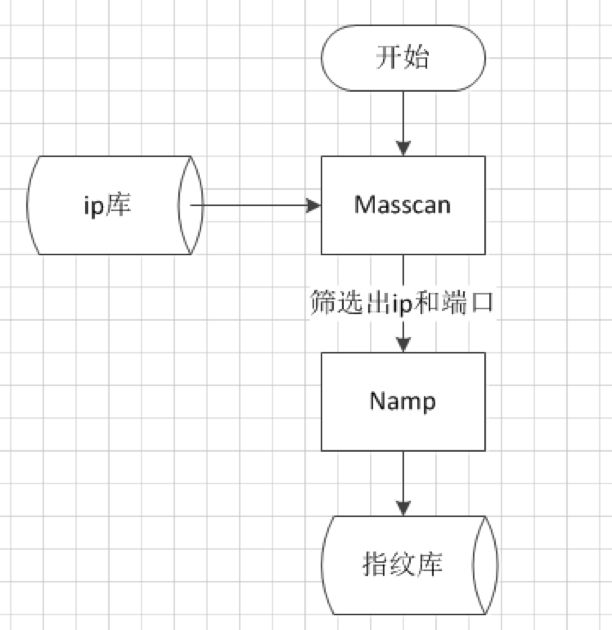
主机层面的指纹识别主要包括os、服务和类库的信息,以及端口和banner信息。端口和banner信息可以通过masscan + nmap的方式获取,而os、服务和类库的信息则需要服务器上的agent端获取。
端口扫描主要获取端口开放信息、服务以及端口对应banner,由于ip数量众多(公司活跃ip 5万+), 如果只是用nmap扫描全端口,扫描时间将非常长,因此可以首先使用masscan对全ip进行粗略扫描,然后针对masscan获取到的ip和开放端口使用nmap进行精确测试:
端口扫描服务该内外网分开部署,同时进行镜像备份,并且在某一个扫描服务挂掉后立即拉起另一个扫描服务,并在挂掉的部分继续扫描,从而降低重复扫描开销,极大地保证扫描效果。目前来说可以将扫描8w+ip时间压缩在1天以内。
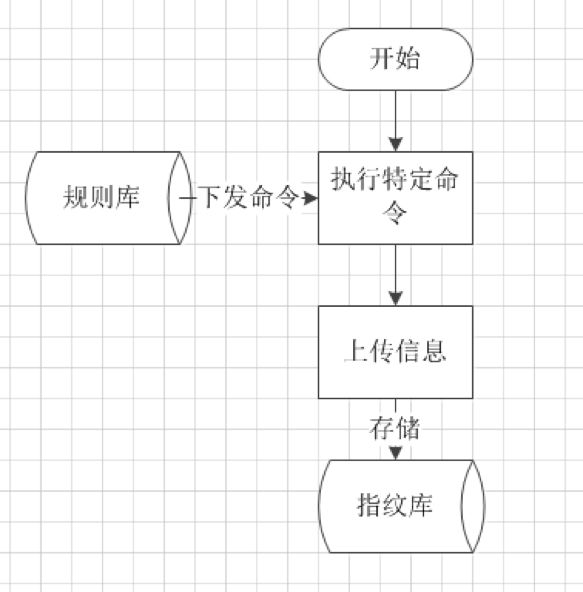
主机指纹采集,主机指纹采集的信息包括机器名、ip、组件名和版本,机器名和ip可以直接获取,组件名则根据规则制定。而获取版本则需要通过下发命令获取,为了排除服务器安装但未使用的服务,需要首先通过ps aux|grep servicename|grep –v “grep”判断指定服务是否开启;针对开启的服务、os或类库,有多种方式可以获取到版本:
1. 服务本身命令,例如php –v等
2. 读取特定文件获取版本,例如cat /etc/issue|awk ‘NR==1{print}’获取操作系统版本
3. 通过rpm查找,例如rpm –qa|grep “^libname-[0-9]\{1\}”
4. 通过文件md5获取,针对某些类库,直接上传类库md5,然后将md5与已知版本类库做比较。
0x03 代码指纹识别
代码指纹识别是指在代码上线前识别代码中的应用指纹,例如java中使用的类库或者PHP中的web框架等。代码指纹可以复用白盒web指纹规则,同时由于不再以机器名为维度,改为通过代码库进行区分。代码指纹识别还可以与数据相关联,用于排查数据泄露。典型的识别规则为:
^import\s*[a-zA-Z0-9_,\s]*(?:cgi|flask|web|django|pyramid)(?:\.[a-zA-Z0-9_]+)*[a-zA-Z0-9_,\s]*$
通过正则可以识别python相关项目,准确性很高。而代码指纹还可以通过与线上机器名与ip关联,从而增加指纹数据维度。
指纹平台实现
考虑到安全应急场景下需要检索全字段、全文匹配的需求,指纹平台后端在进行指纹聚合时使用了 Elasticsearch 数据库;考虑到除了常态化的例行采集指纹之外,还会有高危应急特征的采集场景,指纹平台的后端实现了一个分布式的采集任务调度集群,以灵活支撑不同的任务类型、优先级。
指纹平台总体可以分为三个部分,Web展示、交互与采集和数据处理部分,整体架构如下图。
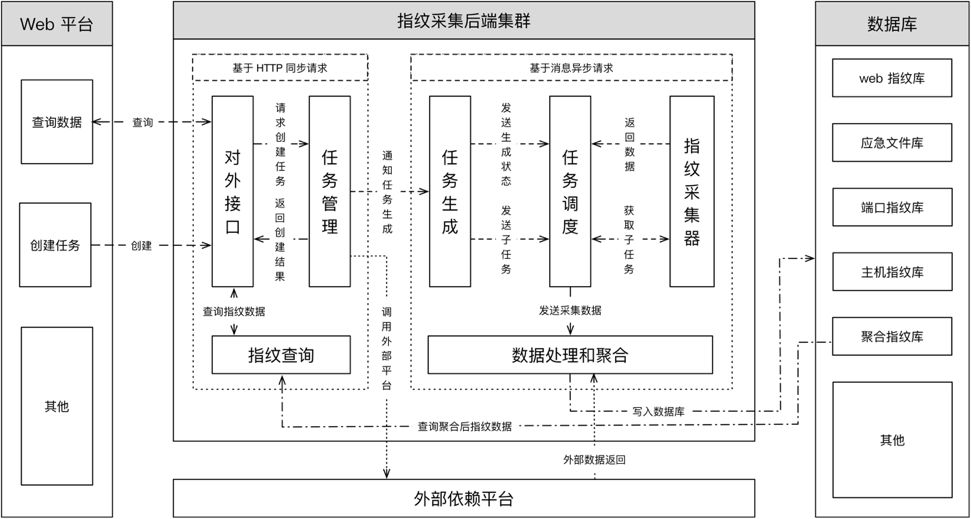
所有的采集请求会先通过对外接口进行基本的信息校验,然后转发给任务管理模块创建采集任务。
任务管理模块接收到请求后会创建采集任务、记录相应信息,然后根据任务类型执行不同操作。对依赖外部平台的任务,任务管理模块会转发通知给外部平台进行采集;不依赖外部平台的任务则构造任务生成请求并写入任务生成队列。
任务生成模块负责对任务进行细粒度的拆分,例如针对公司所有对外的域名库、IP库甚至 Url 库进行指纹采集时,任务生成模块可以根据需求将任务拆分成多个粒度更小的子任务,以增加任务的并行能力,减少指纹采集的耗时。同时,任务生成模块也会在任务拆分的同时,针对不同类型的任务为子任务设置不同的优先级,这个优先级将会影响不同任务的子任务之间的执行顺序。例如在某些安全应急场景下,安全应急工程师希望针对一条全新的指纹特性进行快速扫描,只需要创建一个安全应急采集任务,它对应的所有子任务都将会以最高优先级执行。
一个采集任务最终能否被执行,在什么时间以怎样的顺序执行,这一切都是由任务调度模块来决定的,任务调度模块的核心是对执行的控制和状态的跟踪。所有生成后的子任务最终都会被写入到任务调度队列等待执行。指纹采集器会主动向任务调度模块请求子任务进行执行,任务调度模块会根据子任务的优先级、等待时间、子任务采集目标的闲忙状态,采集器的类型等因素来决定是否提供以及提供哪个子任务给采集器执行。任务调度模块也维护着所有采集任务与子任务之间的关联,所有子任务的执行状态。当一个子任务执行完成后,会将采集到的数据发送给数据处理模块。当一个任务的所有子任务都执行完成后,会通知任务管理模块任务结束。
指纹采集器是采集任务最终落地执行的部分,在指纹平台中,指纹采集器根据其所在的机房、机器的配置等信息被分为不同的类型,指纹采集器向任务调度模块请求任务、执行并最终将采集结果发回给任务调度模块。
数据处理模块负责采集结果的处理和入库,指纹平台最终提供查询的数据涉及了不同的指纹类型、不同的采集方式,数据处理模块会根据指纹类型的对应更新聚合指纹库。值得一提的是,指纹的聚合也同样是依托于使用场景的,指纹平台的聚合指纹库中,实际分别存储了基于不同使用场景维度的指纹信息。比如用户想要搜索一个标签为Nginx 的信息时,可能是想要搜索安装了 Nginx 服务的机器,也可能是想要搜索使用 Nginx 提供后端服务的域名。所以不要将所有类型的指纹数据都尝试强行聚合到一起,这样在使用时会带来不便。
指纹平台信息展示
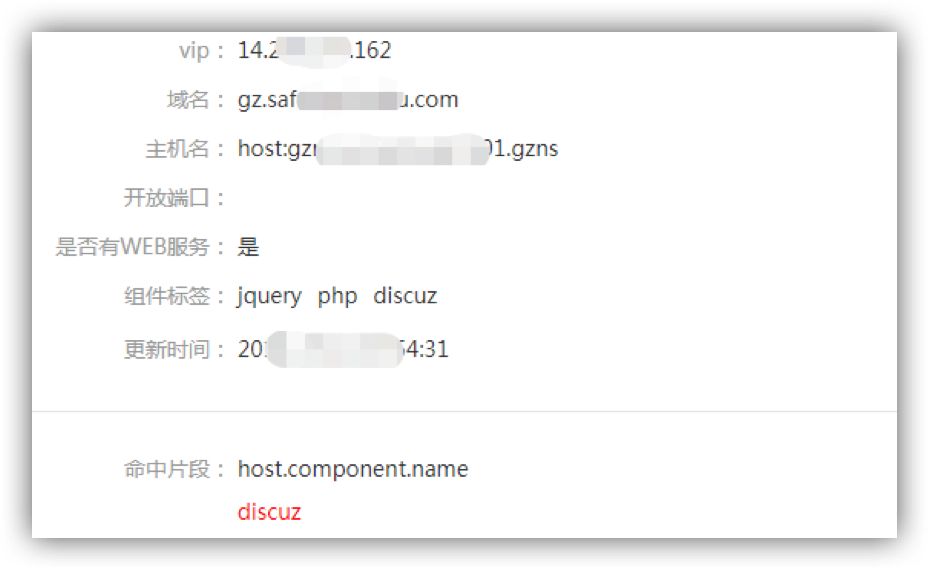
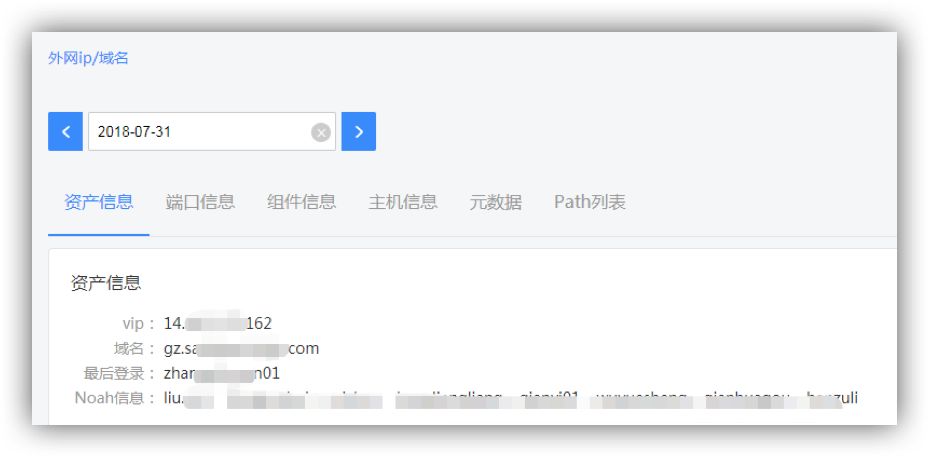
指纹数据主要参照shodan和zoomeye,以卡片形式展示,同时支持多语法搜索,包括的信息有:
端口信息:开放端口、banner以及服务名
组件名:web和主机组件,组件名称和组件版本号(如果存在)
主机信息:操作系统类型、服务列表、类库以及各自版本
元数据:主要为通过各个扫描方式获取上报的指纹信息原始字符串,包括域名、url、web返回响应信息
资产信息:包括ip、域名以及归属人、最后登录人等,便于应急排查过程中定位到具体的业务方
搜索语法主要是为了方便使用者快速查询信息,支持key=value形式搜索方式,部分语法为:
1、全文搜索
例如wordpress,jboss
2、搜索端口
例如port=”80”
3、搜索某个域名
例如host=”xxx.xxx.com”
…
指纹信息展示如下:
总结
相对于外界的指纹平台,公司内的指纹平台,要求多维度的覆盖,这提高了数据的完整性,同样也加大了数据整合难度。在指纹识别的过程中,必须考虑对业务的影响,尽量在闲时采集数据,同时指纹数据的聚合也应该适合从域名、ip和主机名等多维度聚合,并非一条规则聚合所有数据就是合理的。目前我们的指纹平台会例行针对公司的外网域名、IP及 IDC 主机信息进行采集,根据指纹类型的不同,采集一次需要 3 – 12 个小时,采集到指纹数据量在数十万条,覆盖绝大多数 Web 服务器和所有主机,能够满足安全应急排查分钟级数据收集需求,同时指纹平台提供应急数据采集功能,能够针对未知指纹进行1小时内采集。
本文转自 EnsecTeam,作者arnoxia、lSHANG,原文链接