
-
史宾格安全及隐私合规平台3分钟完成一周工作量 更快实现隐私合规
-
IP信誉查询多因子计算,多维度画像
-
智能数据安全网关为企业数据安全治理提供一体化数据安全解决方案
-
4网址安全检测
-
5SMS短信内容安全
-
6百度漏洞扫描
-
7爬虫流量识别
-
8百度AI多人体温检测
-
9工业大脑解决方案
-
10APP安全解决方案
-
11企业人员安全意识解决方案
-
12安全OTA
-
13大模型安全解决方案
-
14安全知识图谱
-
15智能安全运营中心AISOC
热门主题




浅谈中小型企业甲方安全体系建设
2018-12-05 16:22:4732121人阅读
今天分享的内容为讲师所经历以及一些做法,不代表行业观点。仅供参考。
甲方安全其实分为红、蓝两军,而我们要清晰知道这两者之间究竟是干什么的。红攻,蓝守。
先简单讲些下红军日常,以发现公司内外部资产弱点为首,也可以把它当作sdl来看待,蓝军加强内外部安全边界使得红军提高攻击成本或无法渗透进来。
再来把安全的事情定位一下:
1、应用安全
2、移动安全
3、iot安全
4、风控
5、安全合规
6、数据安全
7、IT安全
8、more
还有很多这里就不一一列举了。清晰明确公司需要做哪些,有哪些可以先放一放。
大家可能都觉得在修复漏洞的时候遇到很大的阻碍,先说下背景,我在两家甲方做过安全,但是他们给我的感觉是不一样的,第一家甲方没有人愿意修复漏洞及沟通成本比较大,所以导致没法更好推动漏洞修复。到了第二家甲方任何事情阻力比较小包括沟通,可能是因为公司对待安全比较重视所以才能有这样的效果出现,还有我们需要到一份checklist,整理好后发送给开发看可以更有效规避安全风险。给自己在测试过程中检查还存在哪些问题。后续做成报告形式,通过邮件或者soc平台进行项目人员推送,要让别人知道你是做了事情。还有要清晰知道自己是属于服务部门,在跨部门协作时要懂得巧妙语言交流。
提问题只是完成了一半,提出问题后还要写上修复方案,而恰巧你们有soc平台时,针对漏洞类型录入方案,填写信息时直接选择就能补充,不需要太过复杂。如果没有可能要每次比较辛苦些,需要每次做复制粘贴等操作。。。

(此图来源于某乙方修复方案)
从我眼中看来0-1的安全只不过是在公司发展的情况下加入SDL流程并把它完善到项目开发当中。之前讲过需要给针对特定人群进行安全培训原因无非就是减少自身的工作,像是开发如果给他讲解哪些点容易常出问题,他在某个项目当中开发这个功能出现这样的问题则需要问清楚究竟是为什么会这样,如何才能避免下一次的发生。而安全测试在什么时候接入呢?个人觉得更应该是前后端联调功能完毕后立马进行安全测试,如果等到测试人员冒烟后进行测试已经来不及在上线前完成了,有问题反馈需要时间修复,没问题倒还好说。毕竟风险都是不可控的,需要做到可控的就是教育和规范。
每家甲方都需要做做扫描和监控,漏扫、代码扫描、主机监控、GitHub监控、暗网监控。前段时间某站的事情就是从暗网蔓延全网事情,这里要做的是监控多平台消息,及时止损提前知道消息进行排查,不细讲。而我的漏扫方式是,每天某个时间段针对资产进行扫描,利用awvs、巡风也好,再者从运维中拉取最新的资产,做到及时同步。每天上班时间的x点程序自动推送端口扫描信息,清晰知道哪些资产对外,有什么危险端口。再去盘查为什么要这样做。说明风险。需要记录公司ip、域名、服务、端口、人员等资产信息,避免出事故后在找人方面麻烦(后续会提下“麻烦”两个字),除了记录还需要拥有自身的扫描器去定时扫描相关服务是否存在xx安全隐患然后推动。如外部出现Nday高危或严重漏洞且有poc的情况尽快弥补漏扫平台插件,及时对业务进行扫描,做到迅速发现--弥补等。从而这个流程进行一个闭环过程。当然不是每个漏洞都会有poc,没有的情况下要想这个组件自身有没有,有则研究去复现,无则空闲时研究提高自身技术。
到了后来,我觉得已经很安全了,没有什么点可以做了。回头想了前期发生多次攻击事件,让人很被动,完全属于无感知状态,导致tg有人发消息扬言xx内部权限出售等。虽然对自己做的事情有信心,但你不确定它究竟是否入侵成功。然后我向领导提及要做主机防御,无奈这件事情……现在没有人力资源的情况下毫无自研能力。在这过程期间,我调研了市面上有的主机安全产品,和假设我们要做的情况要有什么功能…
我眼中的防御,分了两步走,一步是web还有一步是服务器。先讲下web,去调研公司现有什么东西,然后可以让我们去调用的。后来调用es平台二次开发后演变成web日志分析,这套产品定位是能感知攻击者在攻击哪些业务,用什么方式攻击,持续时长,是否攻击成功。。这里没有过多的可以讲述。属于半成品,后续如果你想做,我们可以一起深入探讨这个事情。
再讲主机,要知道服务器是否被shell,能否检测反弹,挖矿,写入rootkit等。都是需要我们思考能否发现的,如果少一步漏一步都有可能导致最后结果没有办法清晰溯源到攻击者。像似今日某酒店数据泄漏事件,这其实不排除人为导致的,人为因素有很多,比如把代码含数据库账户密码、连接方式上传至外网,再比如是内部员工与外部结合(内鬼事件)等,都是需要把控的一些方向。
防御的概念还有很多,移动端有给apk加壳加固等,上至WAF下至风控都是一整套的防御,这里先简单讲解下WAF吧。主要防御是外界的一些已知和未知的攻击,已知的攻击可以通过一些指纹识别去判断攻击者采用了哪些手段去攻击。以某云为例
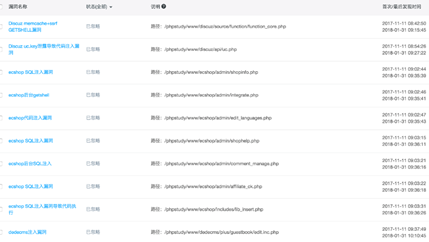
它们有能力去判断你哪些代码会存在什么样的问题然后给你详细写出来具体位置,修复方案等。同理这些我们也是可以去参考做的事情。而不是xx包出问题了升级就可以的,每个业务特性都不一样。如果只是让升级包之后导致业务无法正常运行,那么锅谁来背。

这里稍微讲下webshell的检测吧,可以通过监控指定目录下的所有文件的创建、修改、重命名等操作,再比如说 <?php eval($_POST[1])?>,当代码中出现eval与$_POST时,判断为webshell,但如果只出现eval的函数,就判断为敏感函数。也可以通过webshell hash、文件名等进行检测,在GitHub上就有这么一个项目:
https://github.com/Neo23x0/signature-base/blob/e264d66a8ea3be93db8482ab3d639a2ed3e9c949/yara/thor-webshells.yar
还有就是基于关键字的特征:https://github.com/chiruom/Webshell_finder/blob/master/reservoir.php
通过机器学习的方法去检测webshell:https://paper.seebug.org/526/思路
还有通过机器学习实现PHPWEBSHELL检测:http://webshell.cdxy.me/
另外关于应急响应,如果真的运气不好公司遭到攻击成功且入侵内网机器,但没有安全产品的时候要怎么做?讲一件当时经历过的case,当时经业务部门反馈某应用占用cpu很高而且是特定用户组,寻找了该应用是否存在Nday和挖矿行为,果然在早期就出现过这样的案例,并被分析,当时我们已经清理掉该部门机器中的定时启动任务和kill它的行为,但我们隔一段时间发现它还是中招了,哪怕换了一批新机器,后来想到底哪里出了问题。这时候想到了内网蜜罐系统(后面会讲一下它要有什么功能),可以部署一个蜜罐,节点在生产和测试网络上,去收集是否有机器异常扫描行为。毕竟黑客入侵后肯定会在内网进行扫描等操作,只要命中触发之后我们就可以精准定位了。部署好后,第二天回来看到记录是凌晨三点有两台这种机器在扫描,但非该业务部门的,所以遗留了残骸在内网当中。
这次庆幸的是内网蜜罐起到作用,而该系统需要拥有什么功能呢?它需要统计攻击数据:
1、记录端口扫描行为
2、记录mysql、ssh、ftp、redis等协议爆破行为
3、部署web页面(误让黑客觉得是重要系统,进行登陆操作)其实它怎么输入都是错的。
4、……还有没想到:) 待补充
当然如果waf被bypass 我们需要完善一些机制,去弥补后端的一些平台,即使bypass了前面一层防御,还要主机层等等的防御,要做到的是让你没有办法来到后端进行后渗透操作。
甲方安全不仅是发现后修复,更多的是做好边界安全防御。
今天只是给大家分享我做的一部分事情。
有空可以看https://xz.aliyun.com/t/1250但仅是针对当时写的,后来做了很多事。没有补充在里面了。
今天的分享到这里。后期可以继续深入交流。