
热门主题




AI安全之对抗样本入门-基于PyTorch的FGSM攻击
2019-09-18 16:52:557557人阅读
对抗样本由Christian Szegedy等人提出,是指在数据集中通过故意添加细微的干扰所形成的输入样本,导致模型以高置信度给出一个错误的输出。对抗样本是各种机器学习系统需要克服的一大障碍。它们的存在表明模型倾向于依赖不可靠的特征来最大限度的提高性能,如果受到干扰,可能会导致错误分类,带来潜在的灾难性后果。对抗样本是人工智能面料的最大的安全风险之一。
快速梯度符号攻击Fast Gradient Sign Attack(FGSM),即通过在提督方向上进行添加增量来诱导神经网络对生成的新数据进行误分类。这种攻击非常强大,而且直观。它被设计用来攻击神经网络,利用他们学习的方式,梯度gradients。这个想法很简单,比起根据后向传播梯度来调整权重使损失最小化,这种攻击是根据相同的反向传播梯度调整输入数据来最大化损失。换句话说,攻击使用了输入数据相关的梯度损失方式,通过调整输入数据,使损失最大化。
本文将实现在PyTorch框架上的FGSM攻击。
首先,我们需要定义被攻击的模型。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
model = Net()
模型可以在这个网络的定义上训练,也可以直接加载之前训练好的模型。(网络结构一致)
其次,实现FGSM攻击方法。FGSM的攻击表达如下:
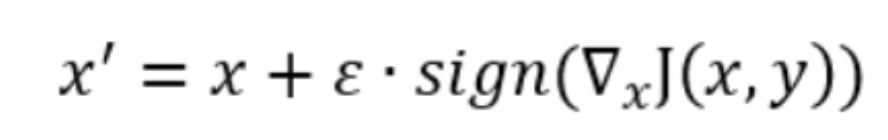

代码实现:
def fgsm_attack(image, epsilon, data_grad):
# Collect the element-wise sign of the data gradient
sign_data_grad = data_grad.sign()
# Create the perturbed image by adjusting each pixel of the input image
perturbed_image = image + epsilon*sign_data_grad
# Adding clipping to maintain [0,1] range
perturbed_image = torch.clamp(perturbed_image, 0, 1)
# Return the perturbed image
return perturbed_image
输入原始样本image,干扰幅度epsilon和梯度data_grad,得到对抗样本perturbed_image
将得到的对抗样本采用模型做验证,如果预测结果与原始样本的预测结果不一致,我们认为该对抗样本有效,是一次成功的对抗攻击。如果epsilon越大,则攻击更容易成功,但同时对原始样本的改变也会更大,更容易被人眼察觉,所以,对抗样本需要在干扰程度和攻击成功率中取一个平衡。
本文由百度安全原创,转载请注明出处和原文链接