深度学习模型容易受到对抗样本(Adversarial Examples)的攻击,这在业内已不是新鲜事。“白盒攻击”中,攻击者往往提前知晓模型的架构和参数,既而针对性的生成“对抗样本”,诱导模型“指数为马”、无中生有,甚至做出攻击者预设的判别结果。
幸运的是,通常情况下,攻击者未必对深度学习模型内部架构、参数了若指掌,此时制造对抗样本则要麻烦许多,攻击者须对黑盒进行海量查询——反复测试,总会发现些破绽,此乃“黑盒攻击”。2017年arXiv上相关论文显示,为达到95.5%置信度的黑盒攻击效果,研究者发起查询次数需高达10万次。当下,国内外主流科技公司将人工智能技术作为一种云服务提供给用户,其中绝大多数公司仅反馈调用结果,不仅模型结构、参数不可获知,模型的输入规则诸如剪裁、滤波比例也不可预判,庞大的查询量,加之模型入口可预设访问频次限制,这令攻击的成本和难度大大增加。理论上,云端黑盒模型是安全的模型,可有效抵御对抗样本的攻击。然而,在阿布扎比当地时间10月12日-17日召开的HITB + CyberWeek 2019大会上,来自百度安全研究员Hao Xin、Dou Goodman、Wang Yang的最新研究成果显示,云端黑盒模型制造的仅仅是虚假的安全感,当模型架构、参数及输入规则不可知的情况下,攻击者依然可通过有限的查询次数,利用同一张对抗图像,令大部分云端图像分类模型做出错误判断。这是继8月底在新加坡HITB GSEC2019上“连中三元”创当届国内企业议题入选数量第一之后,百度安全在AI模型攻防领域的最新研究进展。HITB(HACK IN THE BOX)是欧洲工业界最具影响力的信息安全会议,每年在阿布扎比、荷兰阿姆斯特丹、新加坡举办,迄今已有16年历史,是一年一度全世界顶尖信息安全研究员及大咖共同分享前沿课题及攻防技术的盛会。于年底阿布扎比召开的HITB + CyberWeek则为全球规模最大的HITB会议。演示中,百度安全研究员针对某云端图像分类服务发起攻击,在未知其模型结构、参数、输入规则的前提下,仅通过2次查询,即令一只英国长毛猫“秒变”成了一棵树(如图1)。2次查询即为攻击的全部过程,简单而言,第1次为一个正常查询,利用云端API的反馈结果构建小量数据集,既而利用这个数据集训练替代模型,第2次查询,利用替代模型生成的对抗样本对云端API发起攻击,攻击过程中,在成功率和对抗样本质量上都有较好的保障。
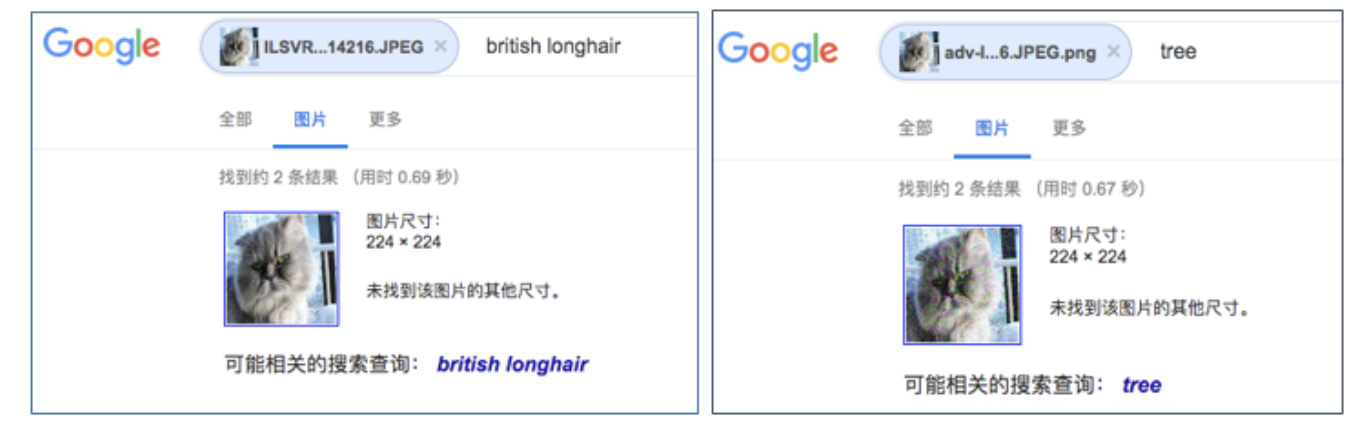
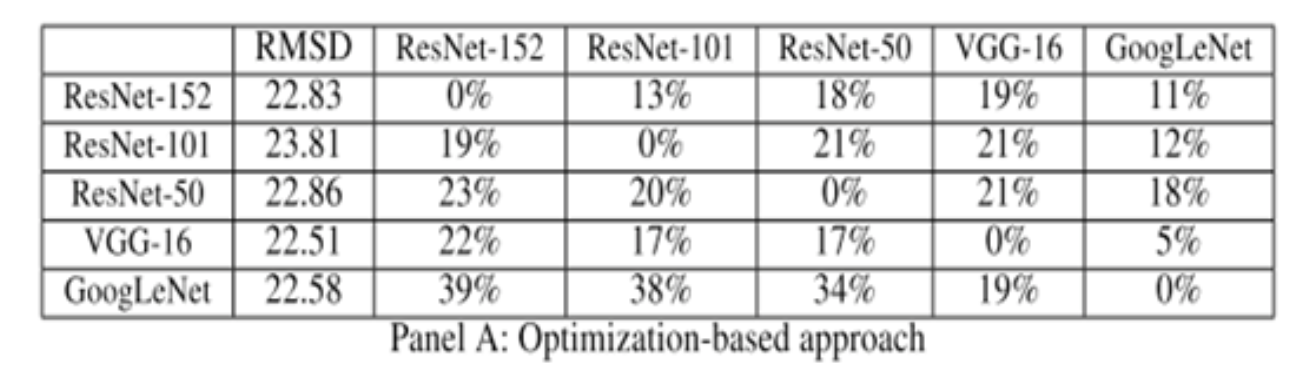
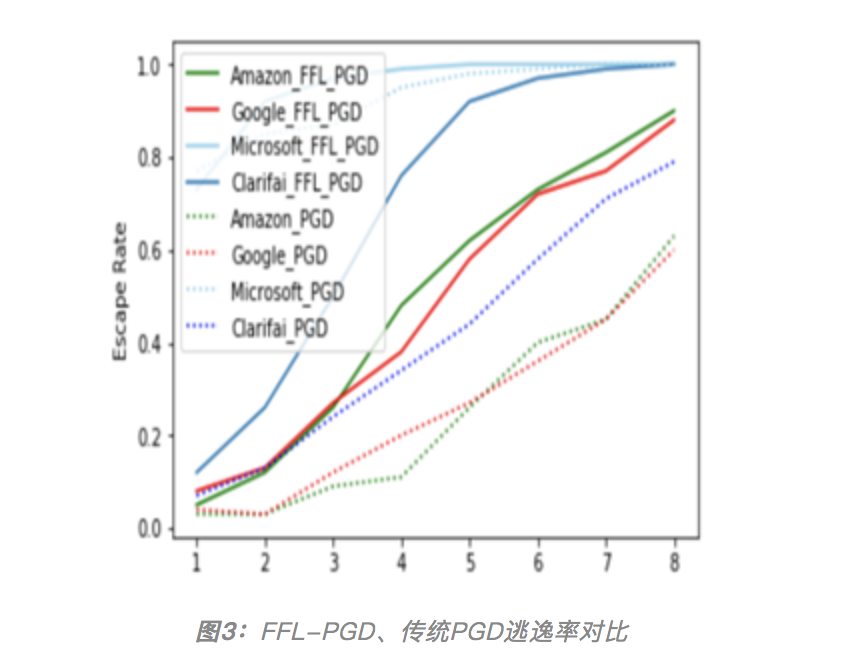
图1:百度安全基于特征图的PGD算法仅通过2次请求,值得指出的是,此前学术界印证云端深度学习黑盒模型安全假象,大都基于迁移学习(TransferLearning)训练方法的缺陷。迁移学习在放宽传统机器学习基本条件、将原先需要几天甚至几个星期的训练时间缩短至几小时甚至几分钟的同时,由于特征提取层的架构、参数在学习过程中被重复利用且保持不变,因此模型所使用的特征提取层可以通过一定的攻击手段推算出来,既而攻击者可按照白盒攻击的方式构造针对性的对抗样本。如图2所示,纵轴为已知模型,横轴为云端黑盒模型,数字为模型正确识别率,数字越小,代表攻击成功率越高,0%即代表100%的攻击效果。这是加州大学伯克利分校计算机系教授Dawn Song及其团队2016年的一项研究。这种攻击方式的挑战在于,如何找到这些具有相同架构、参数的云端模型。无论是针对云端黑盒模型的海量查询,还是基于迁移学习的缺陷,发起有效攻击均需限制在一定的条件下,且部分条件是非常苛刻的。那么,百度安全研究员是如何将理论上可行的云端黑盒模型攻击仅通过2次查询即可实现的呢?在对抗样本的创建过程中,百度安全研究员创新性的提出了一种基于特征图的PGD算法(FFL-PGD:Fast Featuremap Loss PGD),区别于传统PGD攻击仅使用分类损失致使模型做出错误的分类判断,他们在实验中引入了模型多卷积层特征损失,由低层次特征(low-level feature,轮廓、灰度、纹理等)逐层深入,到高层次特征(high-level feature,眼睛、鼻子等),保证这些特征与原模型有更多的不同,从而赋予对抗样本更强大的迁移能力,对拥有相似特征的其它模型进行有效的迁移攻击。除需考量生成的对抗样本的迁移性之外,百度安全研究员也在关注加入对抗样本的图片与原图之间的差距——如果图片被篡改得面目全非或者人类肉眼可见,也便失去了模型攻击的意义。实验中,研究员们用峰值信噪比(PSNR)去测量图片的质量,以及使用SSIM去测量原始图片与对抗样本的相似程度。这也是业界比较对抗样本损失时通用的衡量方法。如图3所示,实线代表用FFL-PGD方法生成对抗样本的逃逸率曲线,虚线代表用传统PGD方法生成对抗样本的逃逸率,X轴表示攻击步长,数值越大,攻击效果越强,图像相对失真率也越大。实验结果表明,基于FFL-PGD的攻击成功率在当下主流云端图像分类服务上的均值超过90%,且每一个分类服务的PGD方法都没有同样步长的FFL-PGD方法获得的成功率高,印证了FFL-PGD具有更加强大的迁移攻击能力。百度安全在AI安全模型攻防领域具有长期的研究与实践成果,从针对Deepfakes“换脸术”的打假、追踪虚假新闻、物理世界对抗本“新思路”生成术,到针对云端黑盒模型的高能效攻击。值得指出的是,目前业界对于AI模型安全的思路大多聚焦于“攻”,关注于对抗样本的生成技术,而无法对模型安全性进行检测。技术一小步,从“攻”到“防”一大步。百度安全业内首创AdvBox对抗样本工具箱,针对AI算法模型提供安全性研究和解决方案,目前已应用于百度深度学习开源平台PaddlePaddle及当下主流深度学习平台,可高效地使用最新的生成方法构造对抗样本数据集用于对抗样本的特征统计、攻击全新的AI应用,加固业务AI模型,为模型安全性研究和应用提供重要的支持。百度安全的研究证明,人工智能时代不仅要面对曾经的云管端的安全问题,机器学习算法自身的安全性亦存在漏洞,存在现实威胁性。百度安全于2018年将首创的七大技术——KARMA系统自适应热修复、OpenRASP下一代云端安全防护系统、MesaLock Linux内存安全操作系统、MesaLink TLS下一代安全通信库、AdvBox对抗样本工具箱、MesaTEE下一代可信安全计算服务、HugeGraph大规模图数据库——开源汇成AI安全“七种武器”,全面解决云管端以及大数据和算法层面的一系列安全风险问题,实现由传统安全时代的强管理向AI时代的强技术支撑下的核心管理的转变,全面应对AI时代下层出不穷且日益复杂的生态安全问题及挑战。